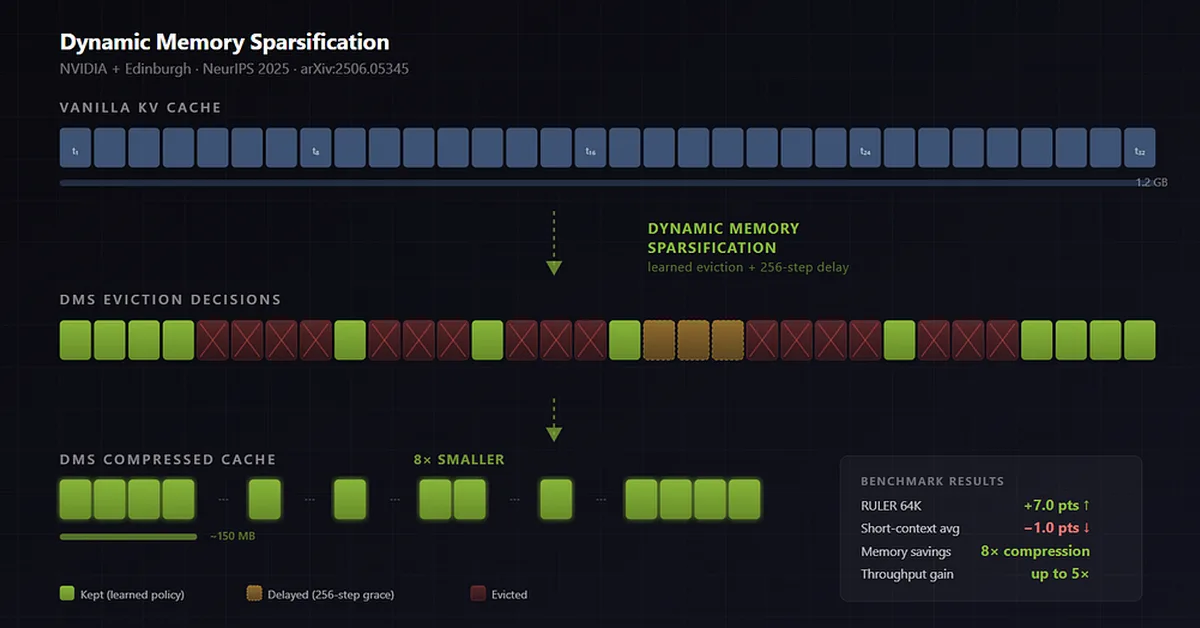
Researchers introduced optimizations to vLLM Semantic Router that significantly reduce latency and memory usage for long-context classification without requiring a dedicated GPU. Key improvements include custom Flash Attention, prompt compression techniques, and near-streaming processing, achieving up to 98 times faster performance while maintaining operational efficiency. This advancement is crucial for content creators aiming to implement efficient large language model routing systems.
Read the full article at arXiv cs.CL (NLP)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
7
Comments

Ali NematiWritten by Ali
![[AINews] The high-return activity of raising your aspirations for LLMs](https://nerdstudio-backend-bucket.s3.us-east-2.amazonaws.com/media/blog/images/articles/c3a8e84bb8954ce7.webp)