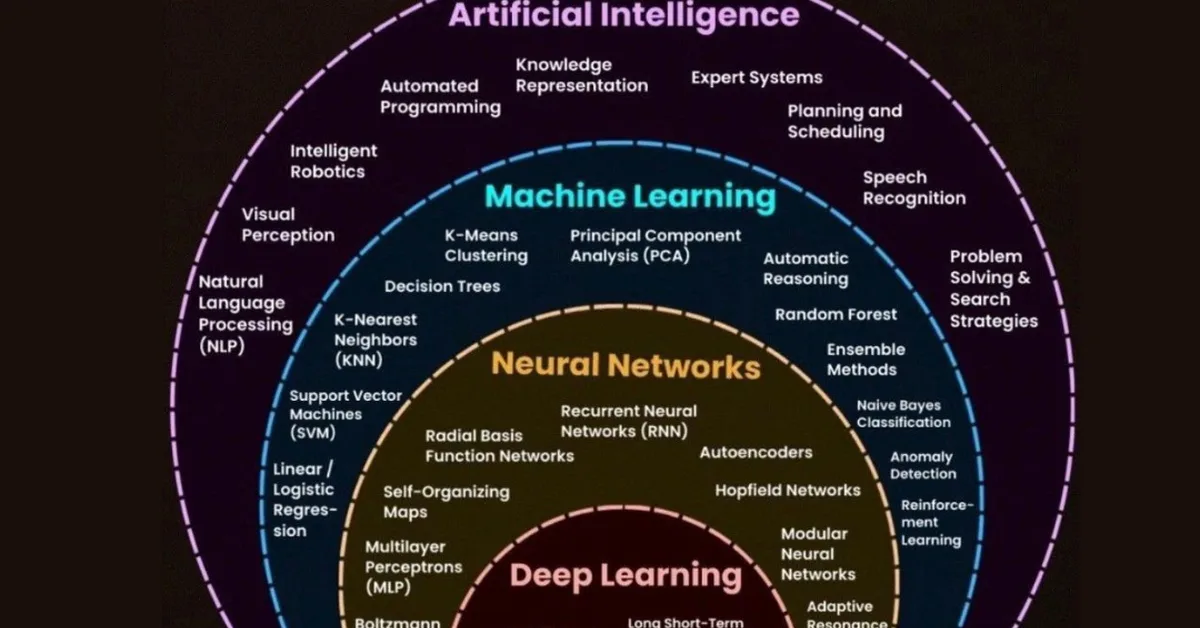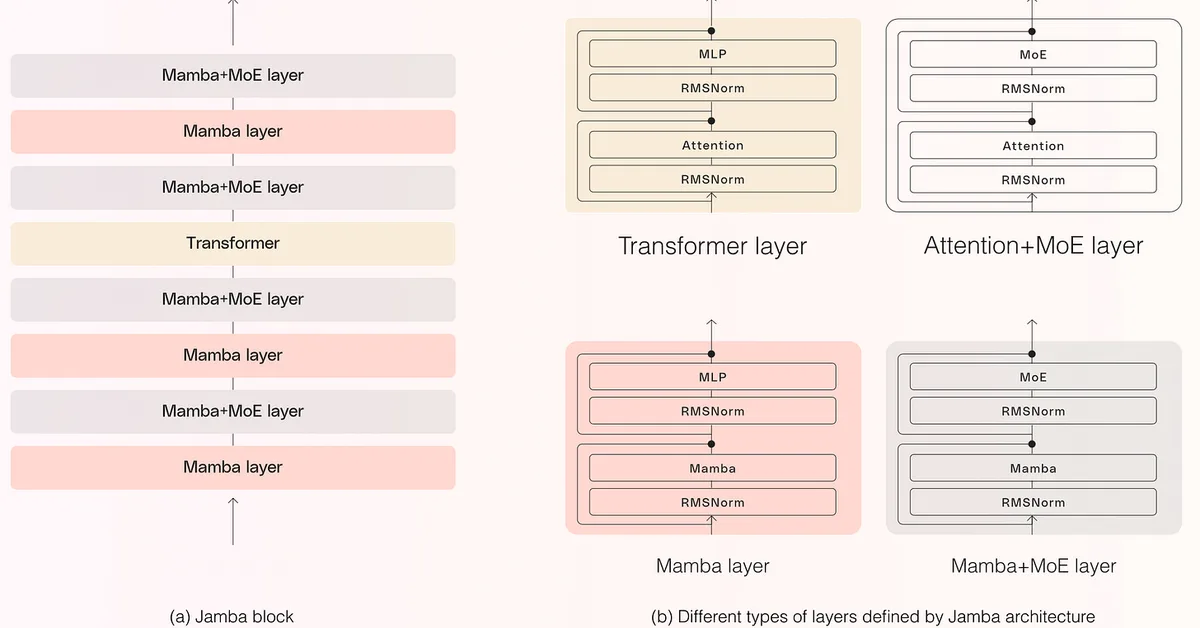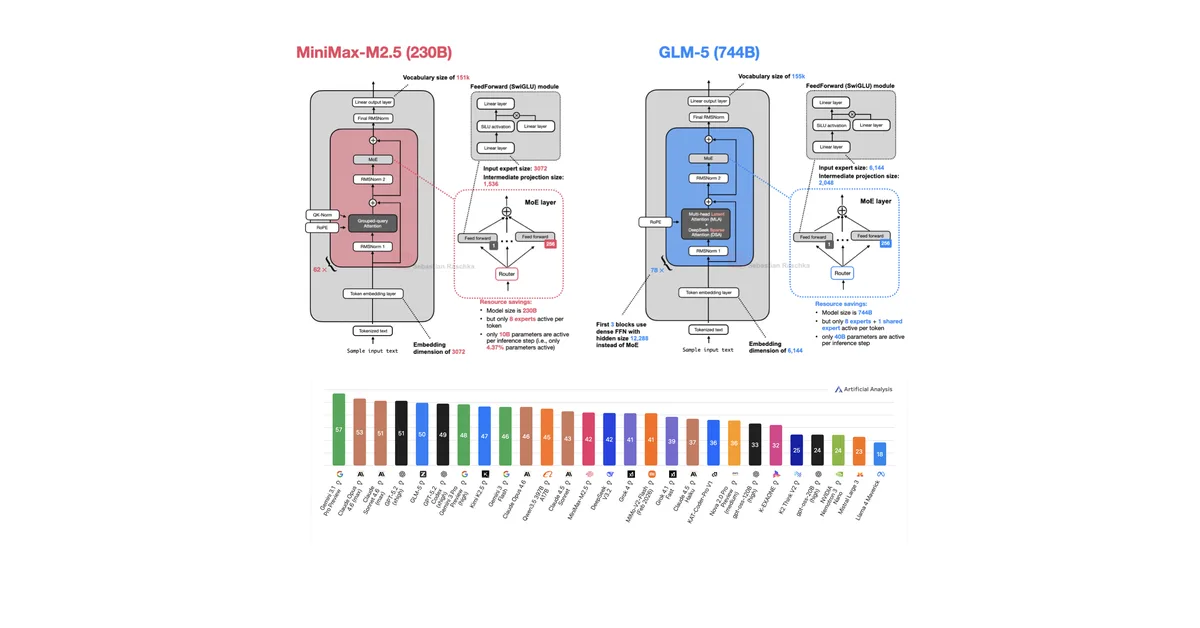
This article discusses recent advancements in large language model (LLM) training techniques and highlights three notable models: Trinity from DeepSeek, Koala from Anthropic, and Step 3.5 Flash from Step. Key innovations include gated attention for improved efficiency, gradual scaling of vision inputs to enhance multimodal capabilities, and multi-token prediction (MTP) to speed up training while maintaining single-token generation during inference. These techniques collectively aim to boost model performance and reduce computational costs.
Read the full article at Ahead of AI
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
112
Comments
AN
Ali NematiWritten by Ali