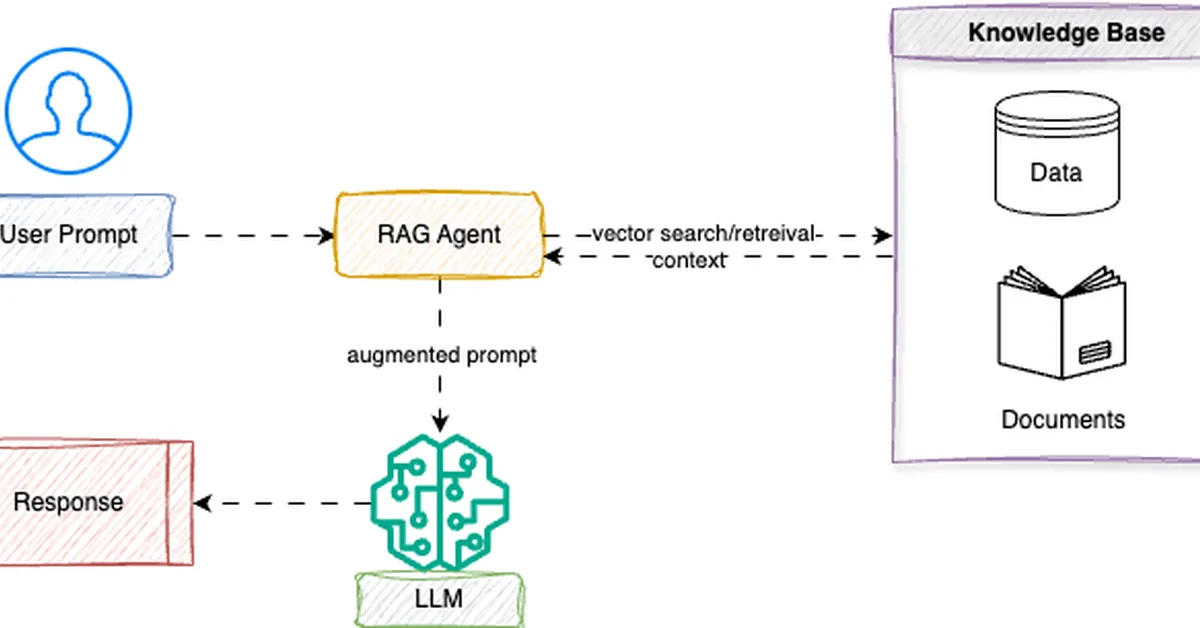
The article provides a comprehensive guide to evaluating AI agents, covering both offline benchmarks and live production monitoring. It emphasizes that agent evaluation is multi-layered, requiring assessment of routing, tool usage, task completion, and more. The text highlights challenges such as training bias and enhancement bias in evaluation models and suggests practical frameworks like AWSLabs AgentEval, Arize agenteval, Eval Assist, LangSmith, TruLens, OpenAI Evals, and Ragas for effective agent evaluation. It concludes by stressing the importance of combining offline and live monitoring methods to ensure continuous improvement and reliability of AI agents in real-world applications.
Read the full article at Towards AI - Medium
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.




