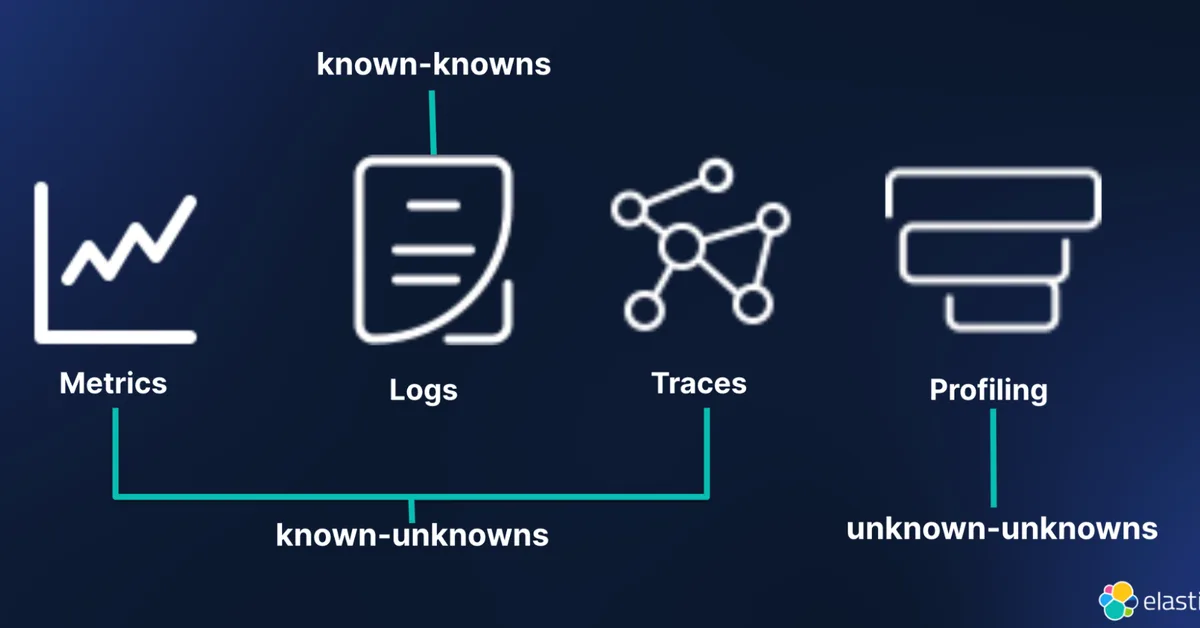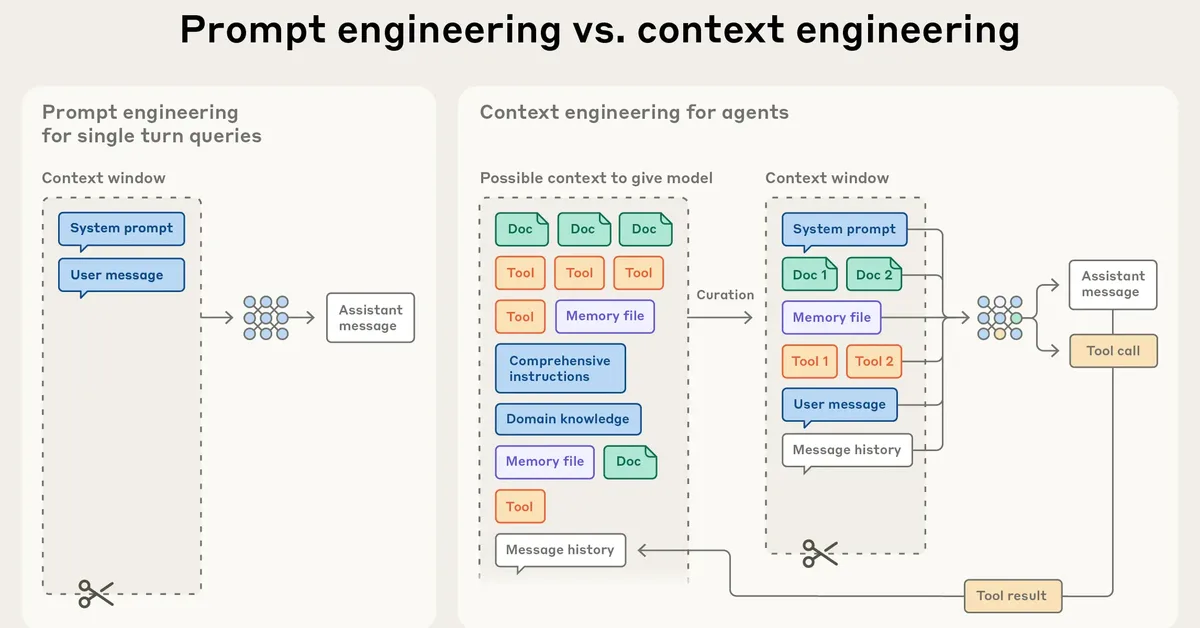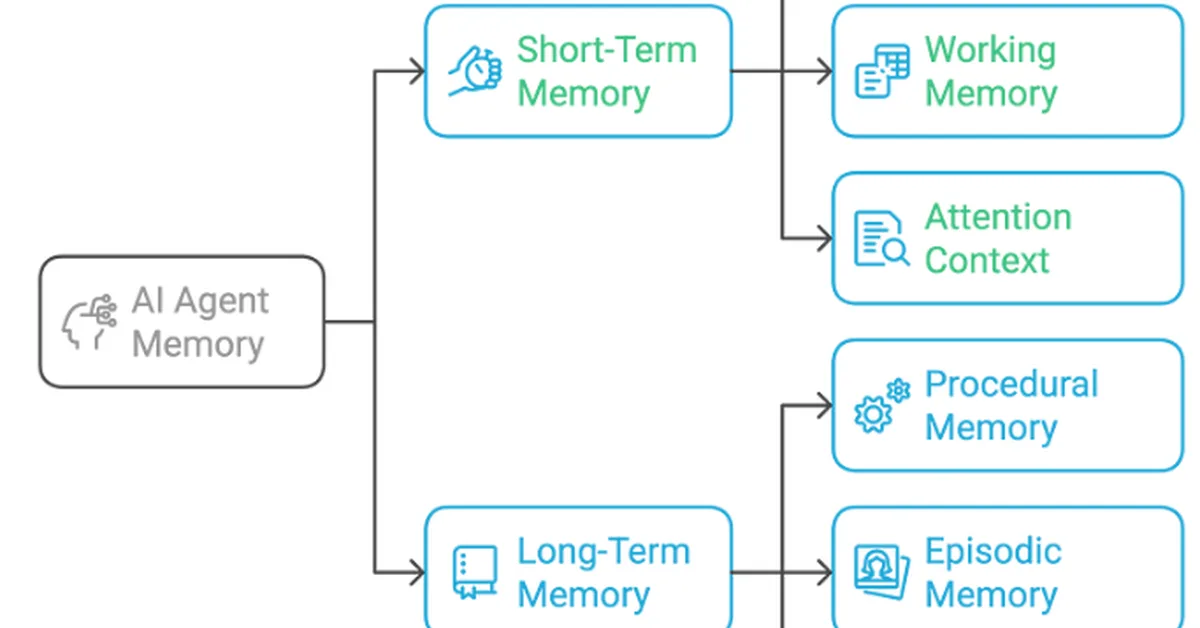
Researchers introduced AMA-Bench to assess long-term memory capabilities of large language models in real-world autonomous agent applications, highlighting a gap in current evaluation methods that focus on human-agent interactions rather than machine-generated data. The key takeaway for content creators is the importance of developing memory systems like AMA-Agent, which incorporate causality and tool-augmented retrieval to improve performance in complex, long-horizon tasks.
Read the full article at arXiv cs.AI (Artificial Intelligence)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
24
Comments

Ali NematiWritten by Ali