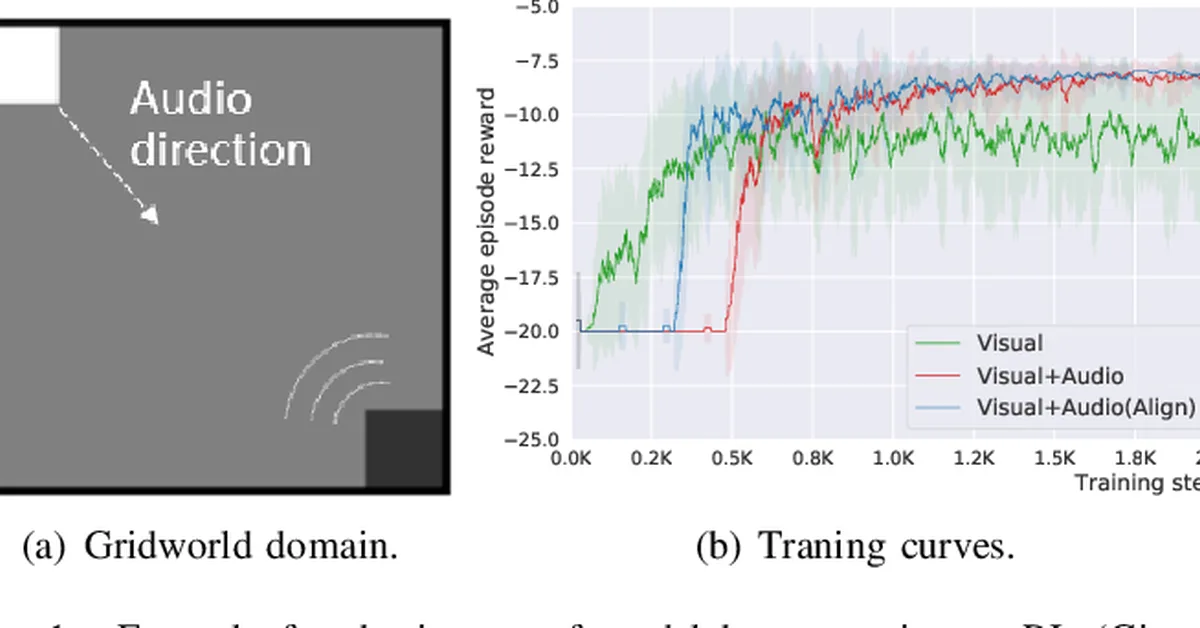
Researchers introduced CalibRL, a new reinforcement learning framework for multi-modal large language models that enhances reasoning capabilities through controllable exploration guided by expert knowledge. This approach mitigates issues like entropy collapse and policy degradation by balancing exploration and exploitation effectively, offering significant improvements in model performance across various benchmarks. Content creators can leverage this method to improve the adaptability and robustness of AI systems used in content generation and analysis.
Read the full article at arXiv cs.LG (ML)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
29
Comments
AN
Ali NematiWritten by Ali