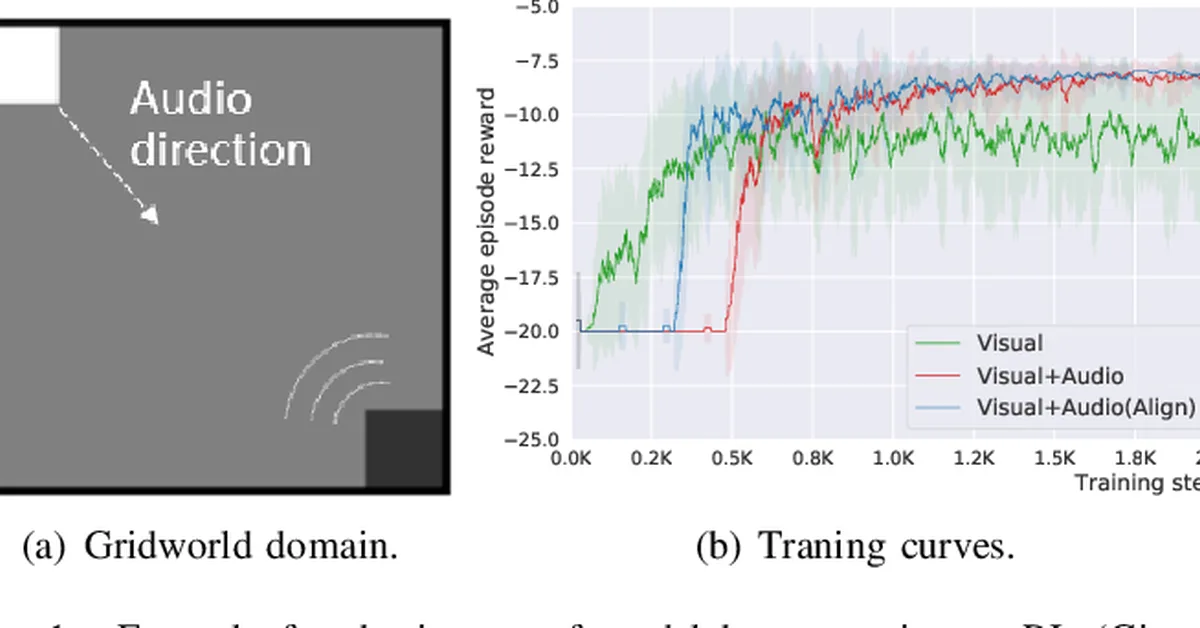
Researchers introduced Directed Graph Policy Optimization (DGPO), which uses reinforcement learning to fine-tune graph diffusion models specifically for directed acyclic graphs used in neural architecture search. This advancement allows for more efficient and effective generation of near-optimal neural architectures with minimal training data, demonstrating the model's capability to learn transferable structural priors and achieve performance close to or surpassing benchmarks.
Read the full article at arXiv cs.LG (ML)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
11
Comments
AN
Ali NematiWritten by Ali