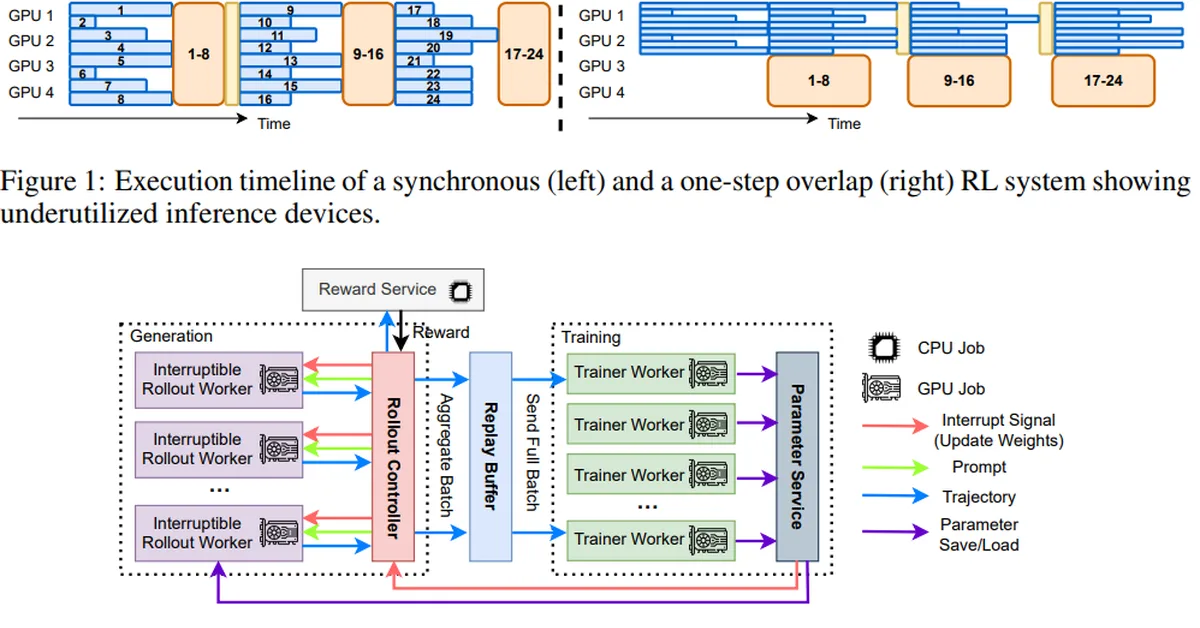
Researchers analyze unsupervised reinforcement learning with verifiable rewards (URLVR) for large language model training, revealing its limitations and potential. While intrinsic reward methods show initial promise, they face scaling issues when confidence does not align with correctness, highlighting the need for external reward approaches that could overcome these constraints.
Read the full article at arXiv cs.CL (NLP)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
4
Comments

Ali NematiWritten by Ali