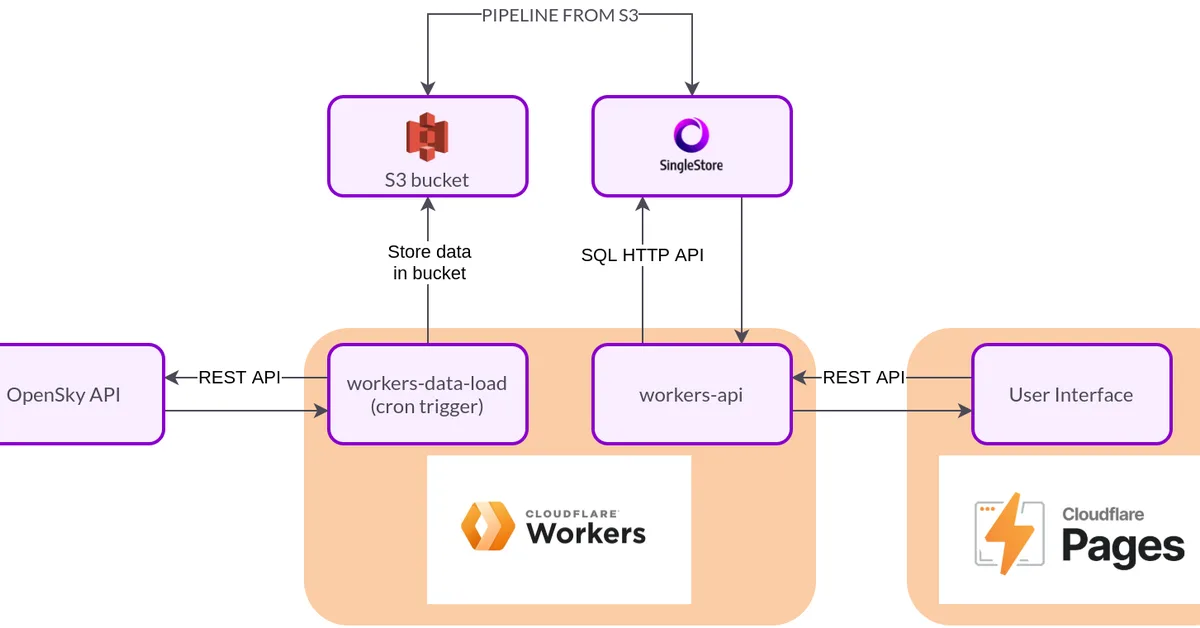
This article details a serverless architecture for creating large ZIP archives from remote URLs using Cloudflare Workers and R2 storage. It avoids traditional limitations like memory constraints by streaming data directly to cloud storage, checkpointing state periodically, and resuming operations after failures. The system has processed over 550K files totaling 10TB of data with no egress fees and peak memory usage under 128MB regardless of job size.
Read the full article at DEV Community
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
8
Comments
Tags

Ali NematiWritten by Ali




