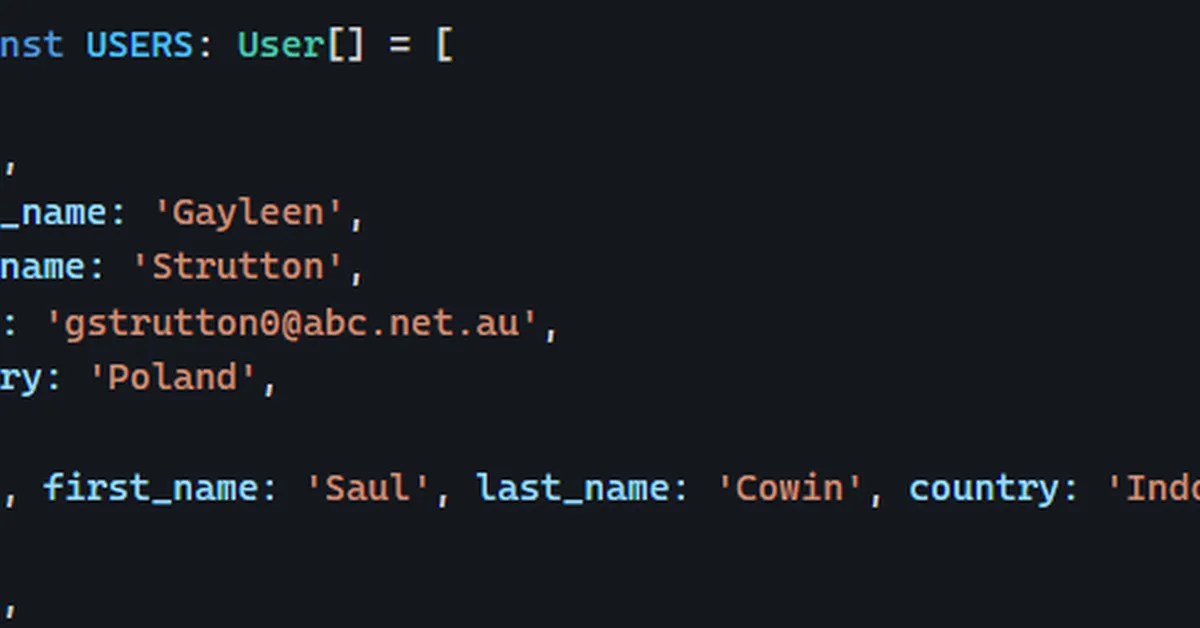
The article describes a method to scrape data from 250,000 Shopify stores without getting blocked, using Rebrowser-Puppeteer and various techniques like script URL matching and DOM element checks. It highlights challenges such as cookie consent managers and error handling at scale, emphasizing the importance of mimicking real user behavior for successful scraping. Content creators can learn effective strategies for web scraping while respecting website protections.
Read the full article at DEV Community
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
6
Comments

Ali NematiWritten by Ali