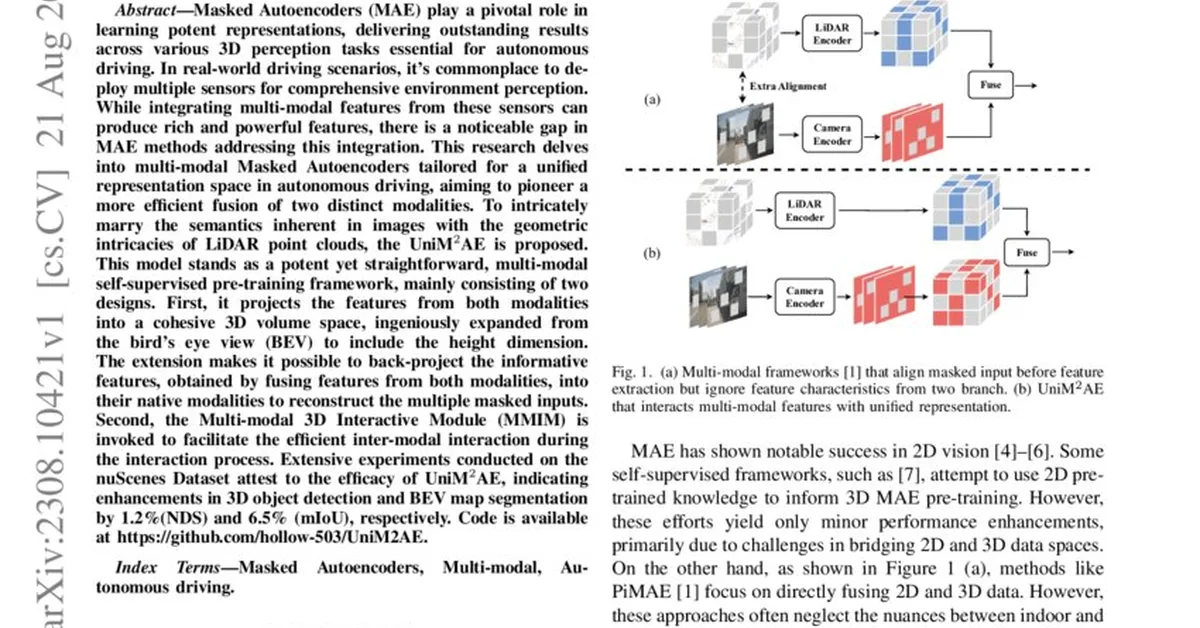
Building a multi-language AI-powered language tutor involves complex challenges such as handling diverse tokenisation requirements for different languages, managing latency to ensure a smooth user experience, and implementing an effective state machine for intent classification. Key optimizations include streaming LLM responses, caching vocabulary checks, running CEFR grading asynchronously, and using smaller local models for error detection. Starting with a robust state machine early on, investing in evaluation datasets, separating the LLM call from grading logic, and budgeting for language-specific engineering costs are recommended practices for future projects.
Read the full article at DEV Community
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.