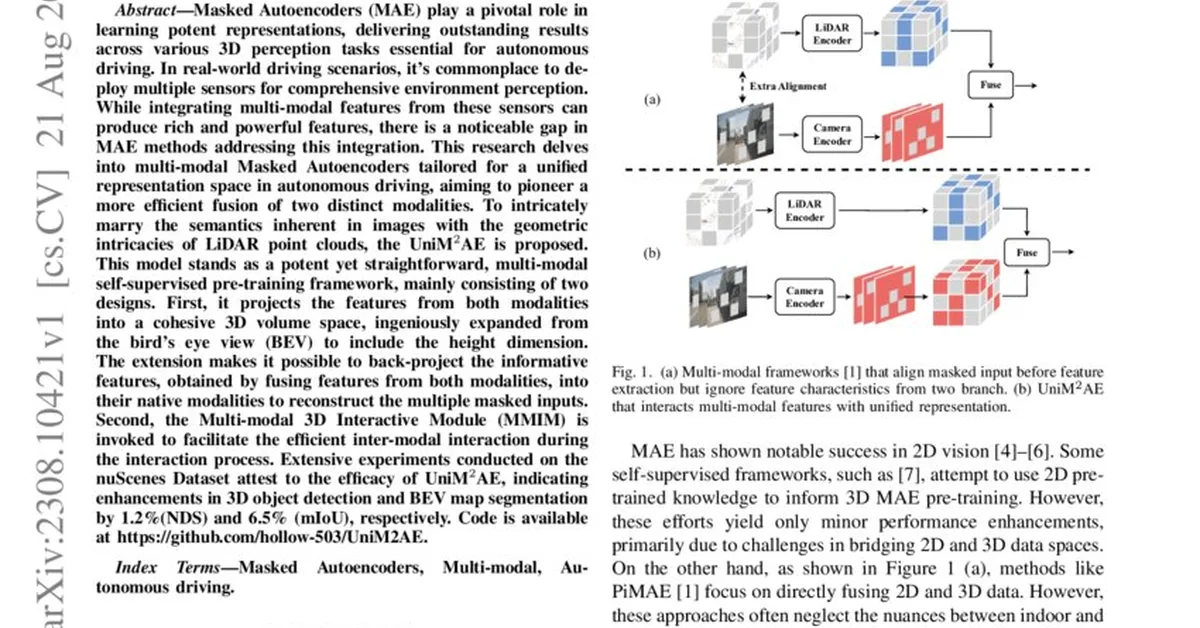
Researchers introduced EGPO, a framework that calibrates intrinsic uncertainty in large reasoning models trained via Reinforcement Learning with Verifiable Rewards, addressing the limitation where high and low uncertainty solutions are treated equally. This advancement is crucial for tasks like mathematics and question answering, as it enhances model performance by optimizing effective reasoning paths rather than just correct answers.
Read the full article at arXiv cs.AI (Artificial Intelligence)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
6
Comments
AN
Ali NematiWritten by Ali