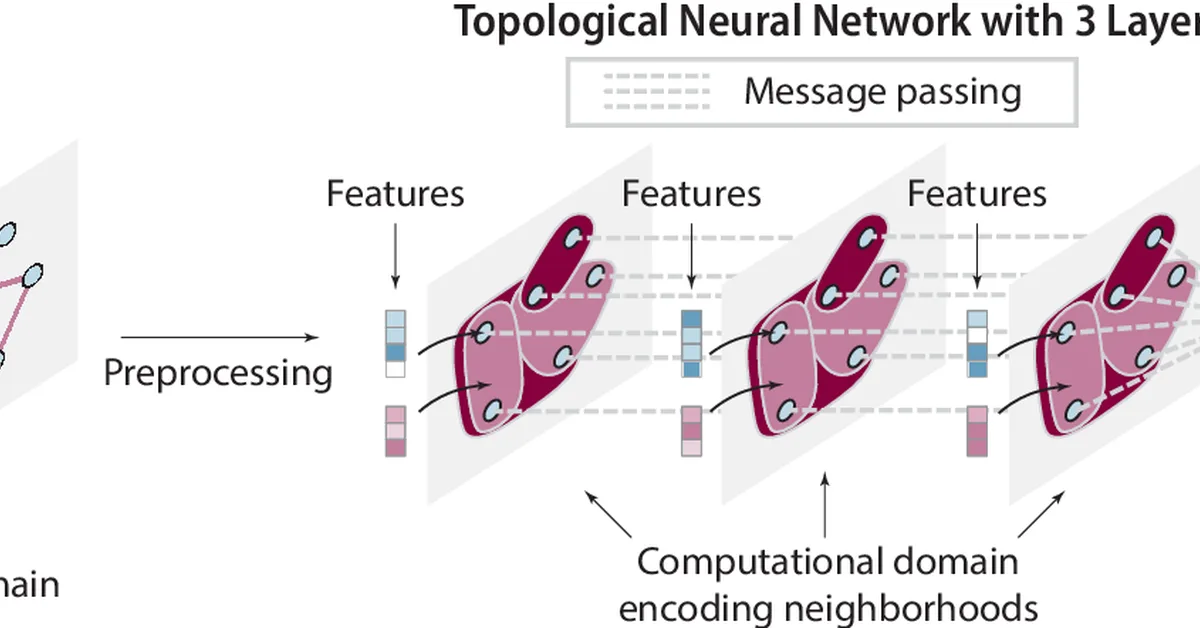
Le MuMo JEPA is a self-supervised learning framework that integrates RGB images with aligned companion modalities like LiDAR depth to learn unified visual representations efficiently. This development is significant for developers and tech professionals as it enhances the performance of multi-modal AI models in tasks such as detection, segmentation, and dense depth estimation while reducing computational requirements.
Read the full article at arXiv cs.CV (Vision)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
10
Comments

Ali NematiWritten by Ali