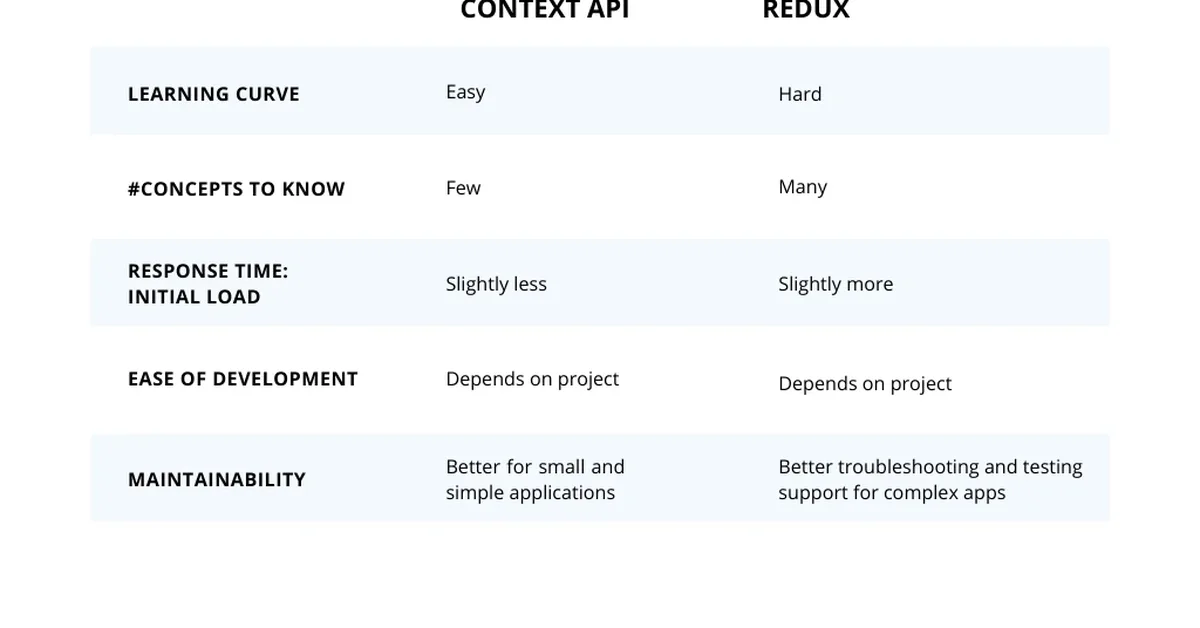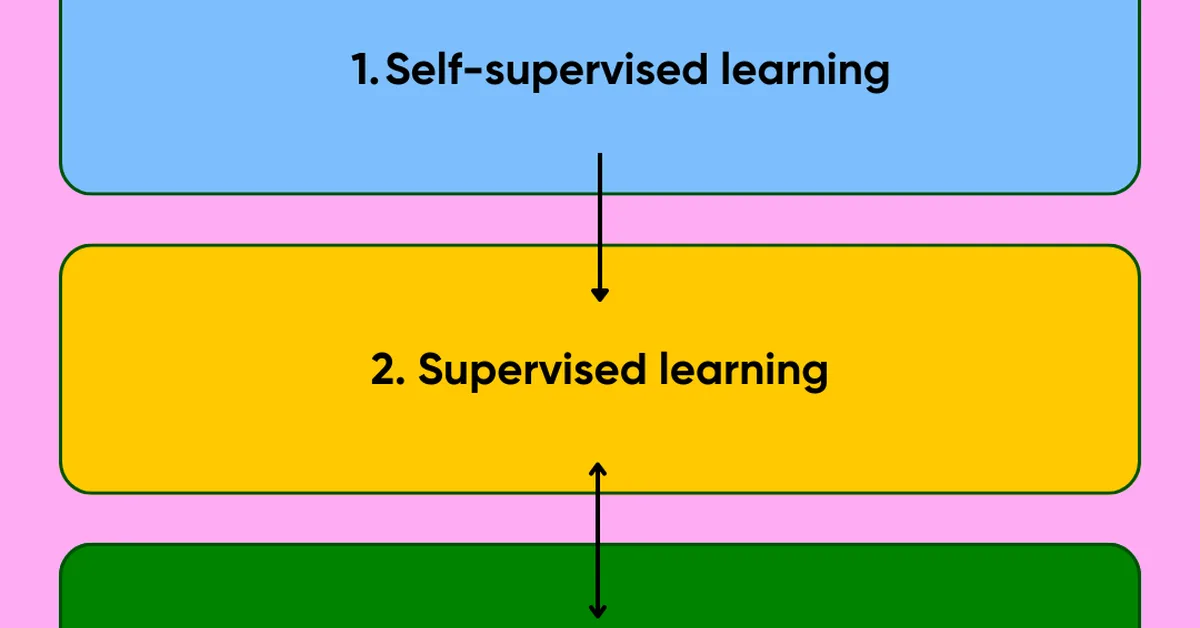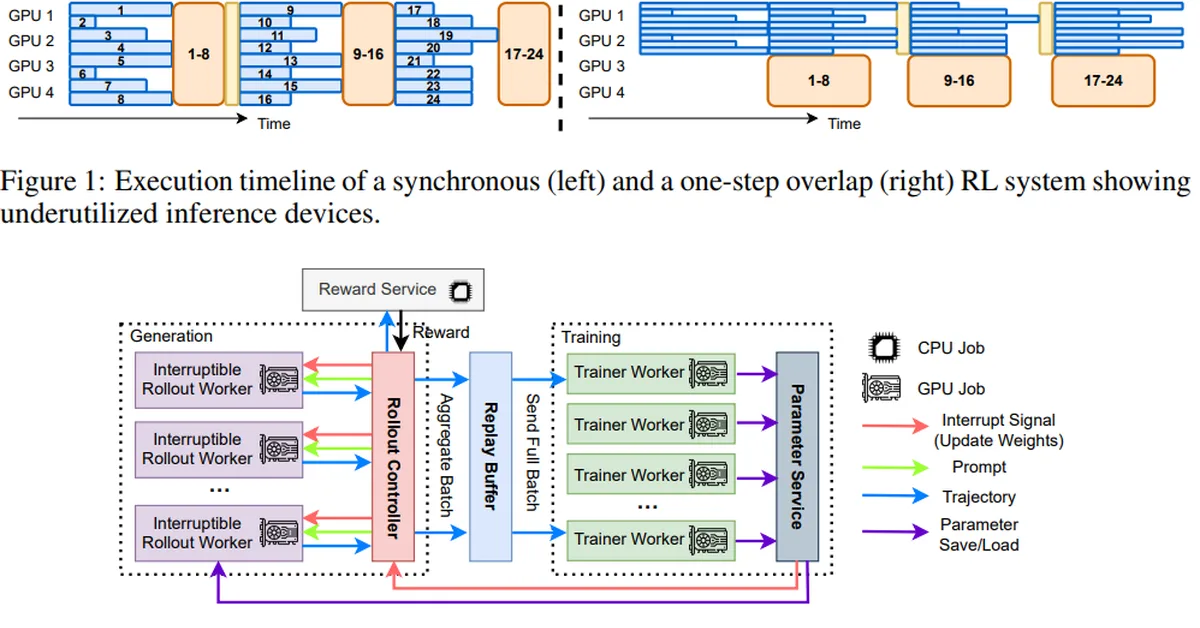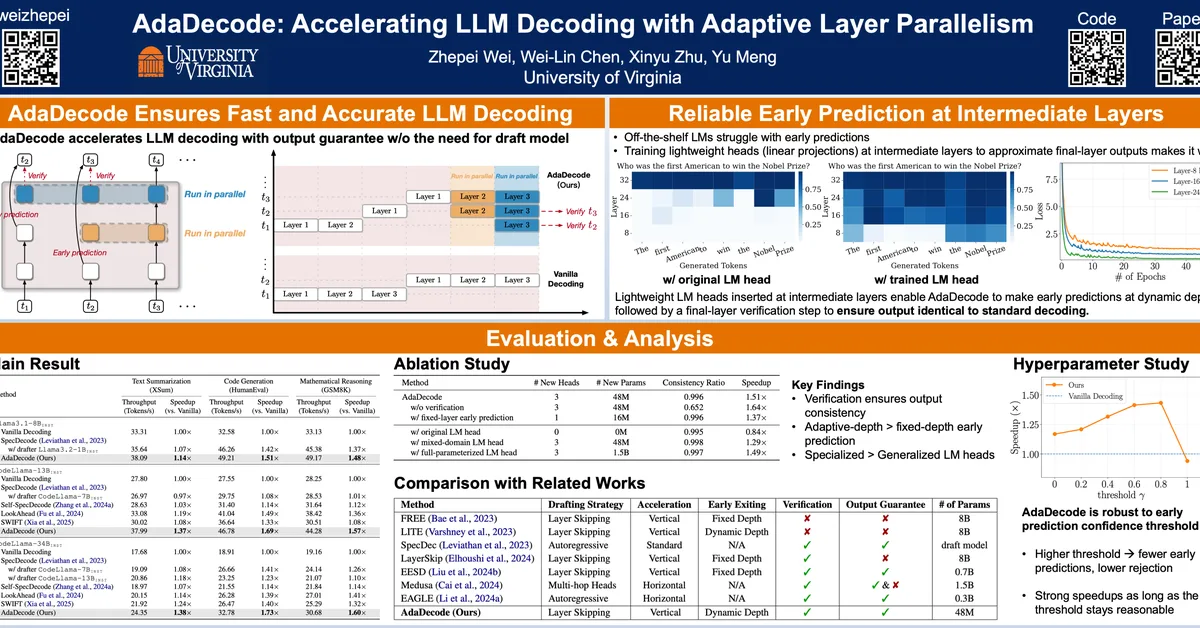
Researchers propose learning adaptive decoding policies for large language models to dynamically adjust sampling strategies based on task difficulty and compute resources, improving accuracy without fine-tuning the model. This approach uses reinforcement learning and can enhance performance in math and coding tasks by up to 10.2% under fixed token budgets, offering content creators more efficient ways to generate accurate outputs.
Read the full article at arXiv cs.LG (ML)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
12
Comments

Ali NematiWritten by Ali