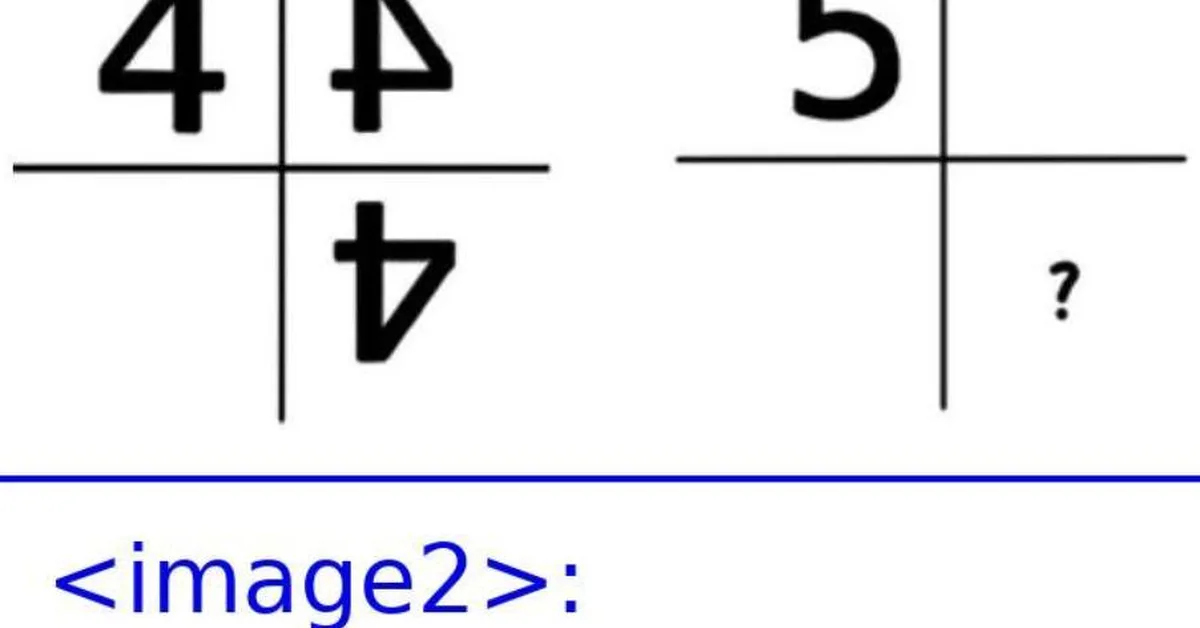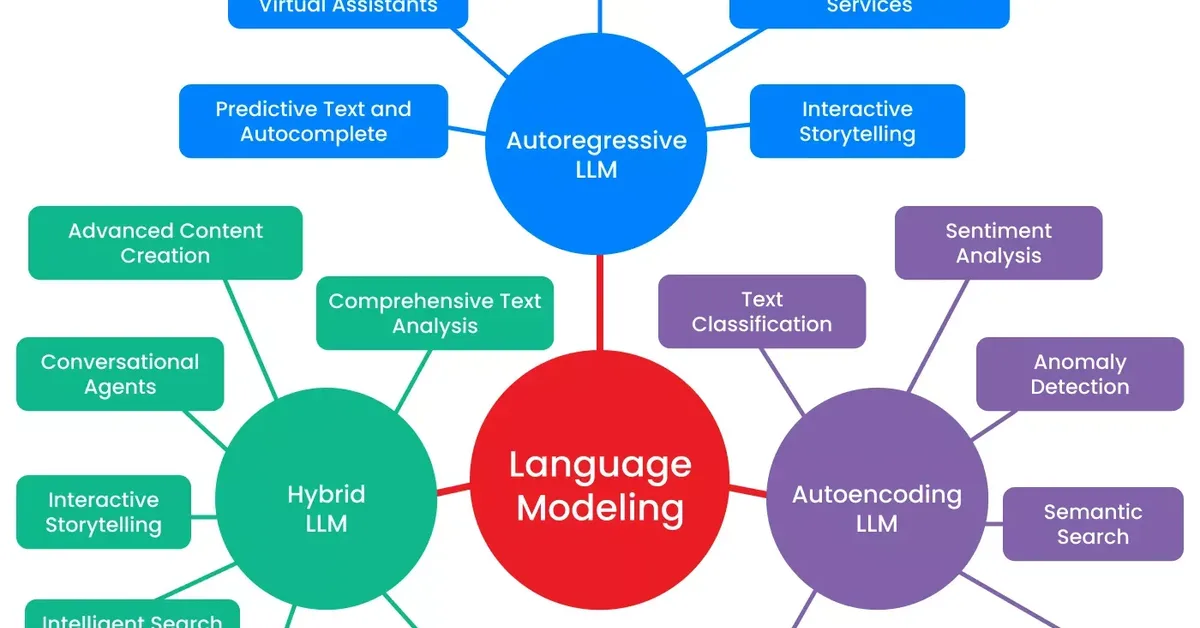
A study published on arXiv reveals that large language models (LLMs) do not equally comprehend all natural languages, challenging the assumption that English is their best-performing language. The research highlights variability in LLM performance across different language families and underscores the need for more diverse training data to improve model reliability for content creators working with low-resource languages.
Read the full article at arXiv cs.CL (NLP)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
17
Comments
AN
Ali NematiWritten by Ali