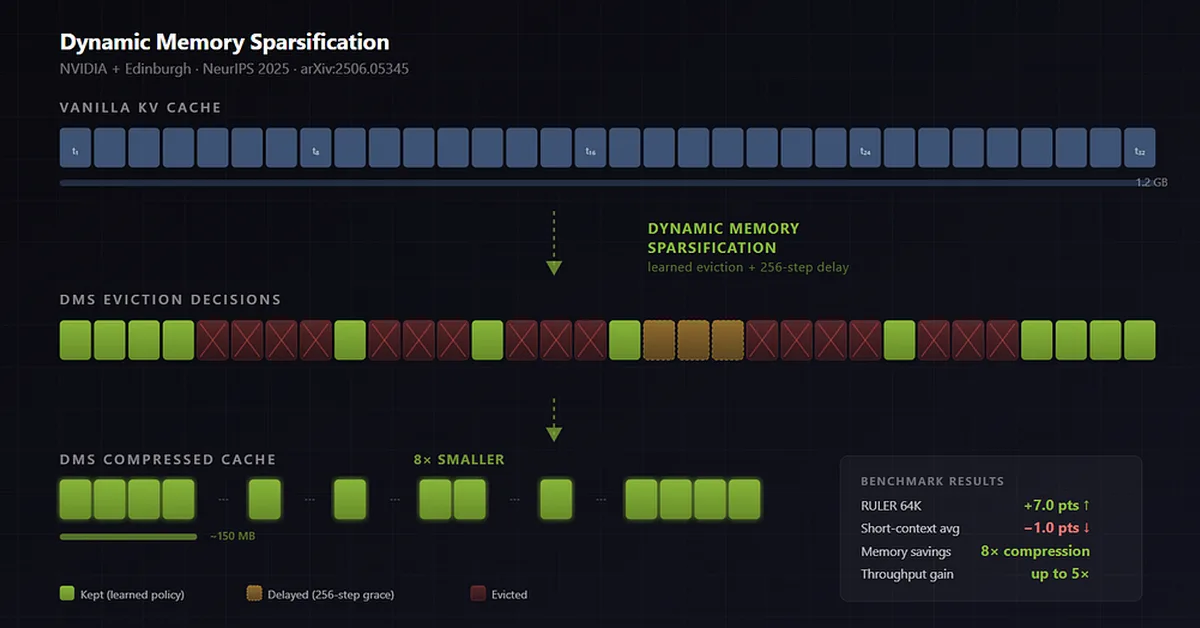
NVIDIA introduced Dynamic Memory Sparsification (DMS) for large language models, which compresses working memory by 8x while improving long-context reasoning and retrieval tasks. This technique offers significant memory savings but may slightly reduce accuracy in short-context scenarios, making it particularly valuable for applications constrained by memory resources.
Read the full article at Towards AI - Medium
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
31
Comments
AN
Ali NematiWritten by Ali