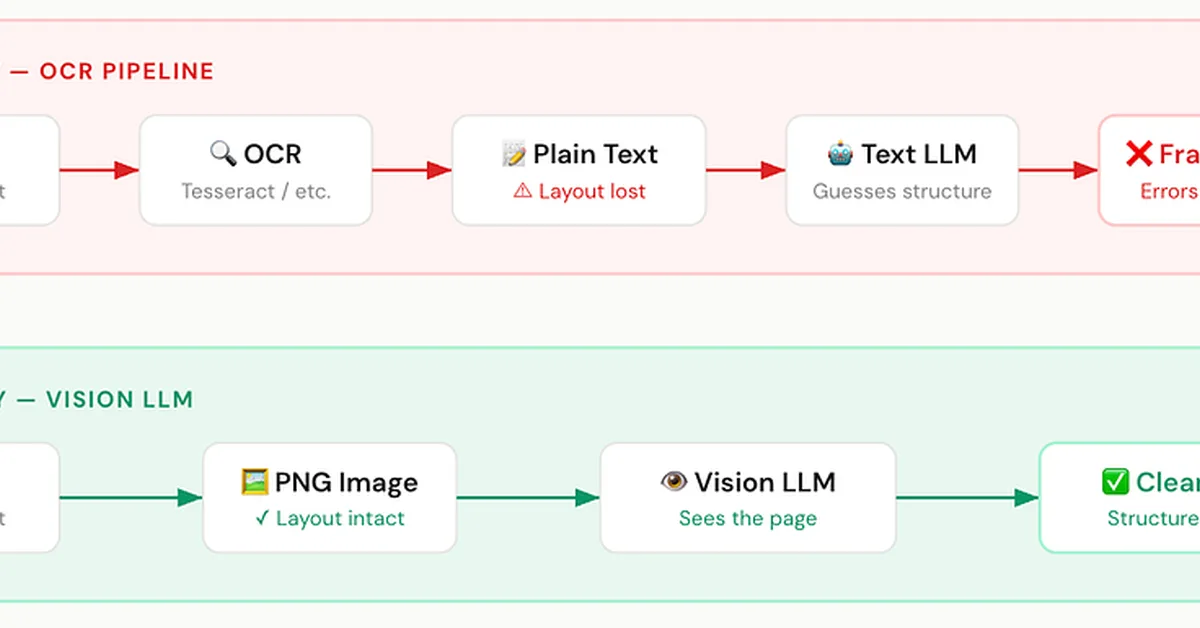
Researchers introduced a data manipulation scheme for monocular 3D object detection that decomposes objects, scenes, and camera poses from training images to recompose them in diverse configurations, enhancing model performance without requiring extensive labeled data. This approach addresses overfitting and insufficient data diversity by creating varied training scenarios, benefiting content creators through improved efficiency and flexibility in dataset utilization for M3DOD models.
Read the full article at arXiv cs.CV (Vision)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
5
Comments
AN
Ali NematiWritten by Ali