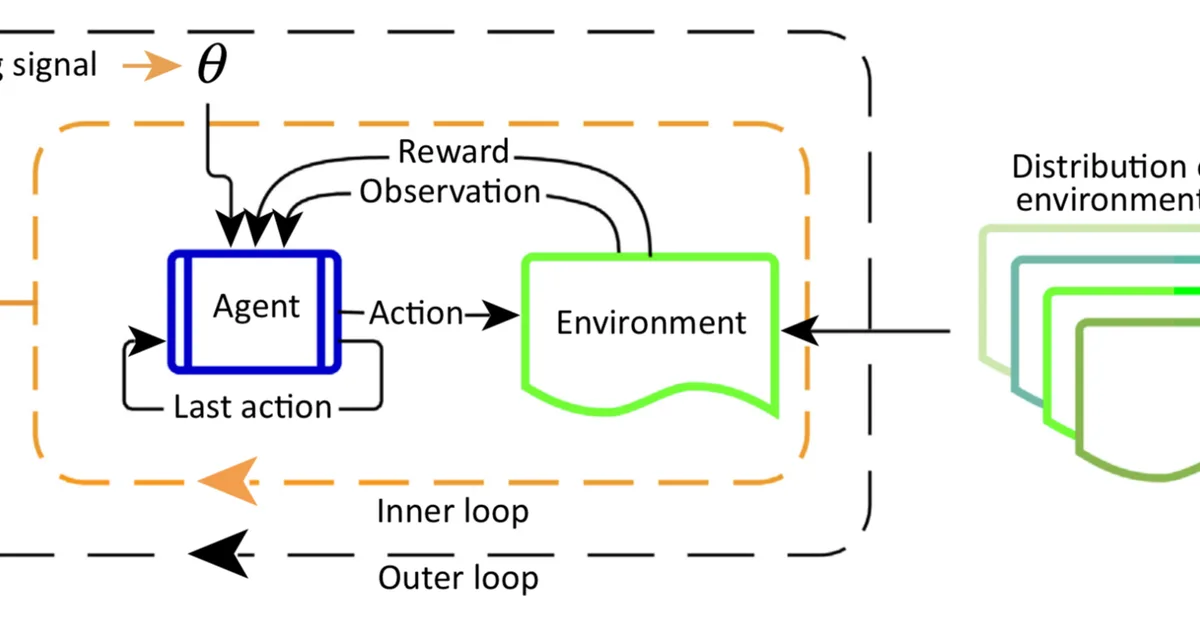
Researchers introduced PolicyGradEx, a two-stage procedure for scalable multi-objective reinforcement learning that partitions objectives into related groups for efficient training, outperforming existing methods by 16% on average and achieving up to 26 times faster speedup. This approach is crucial for content creators aiming to optimize multiple preferences in language models efficiently.
Read the full article at arXiv cs.LG (ML)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
15
Comments

Ali NematiWritten by Ali