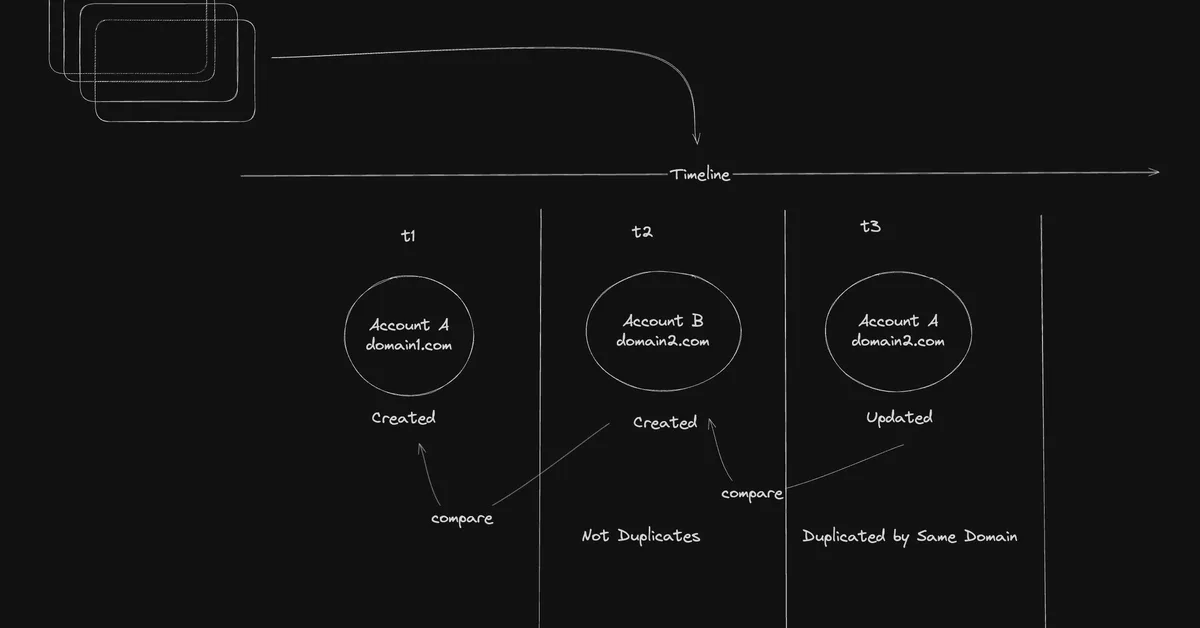
The article discusses how data duplication during model training can degrade performance and lead to memorization, especially as models grow in capability. It highlights that semantic duplicates become increasingly problematic at web-scale due to accelerated semantic collisions, affecting the scalability of large language models. Content creators should be aware that deduplication strategies need to account for both surface and semantic similarities to maintain effective model training at scale.
Read the full article at arXiv cs.LG (ML)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
4
Comments

Ali NematiWritten by Ali




