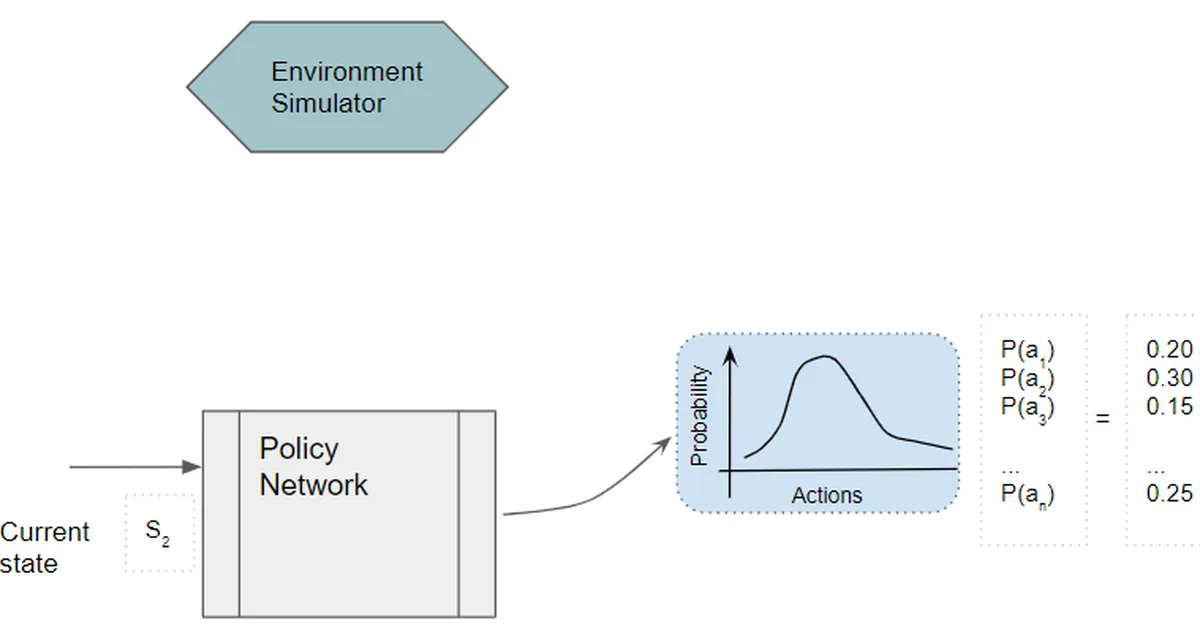
Researchers introduced Visually-Perceptive Policy Optimization (VPPO), a new algorithm that enhances multimodal reinforcement learning by focusing on token perception, which measures visual dependency in generated tokens. This approach improves the reasoning capabilities of large vision-language models across various benchmarks and model sizes, offering content creators advanced tools for integrating visual understanding into AI systems.
Read the full article at arXiv cs.CV (Vision)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
21
Comments
AN
Ali NematiWritten by Ali