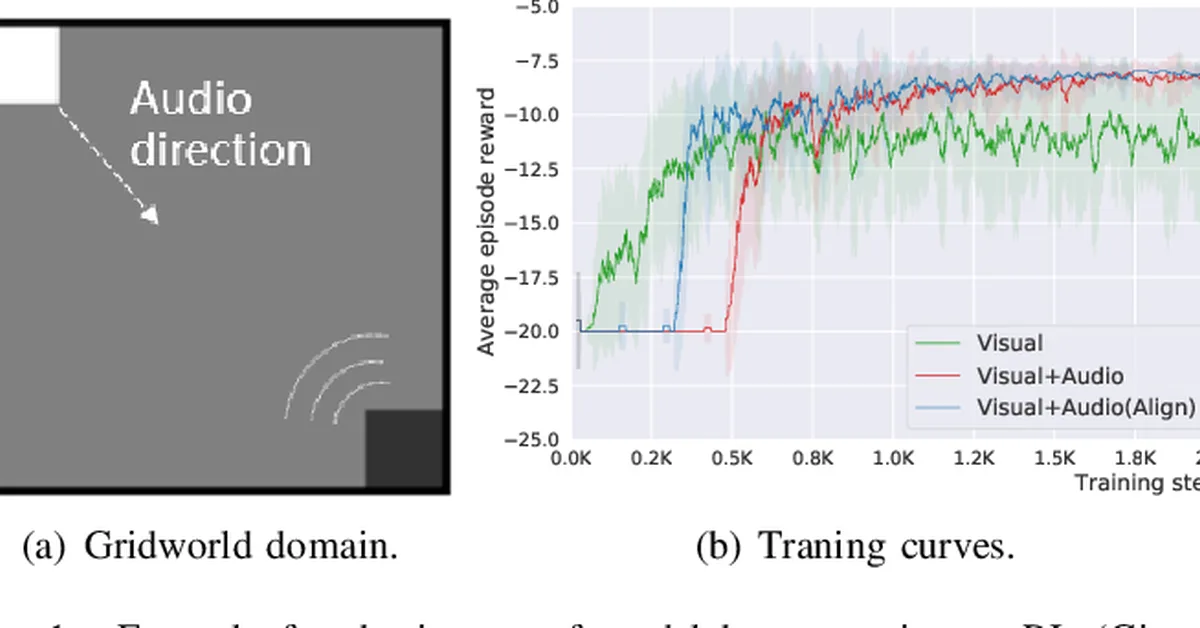
Researchers introduced Curvature-Aware Policy Optimization (CAPO) to enhance policy gradient methods in reinforcement learning, addressing stability issues that require excessive training samples and computational resources. By identifying and mitigating unstable updates through curvature information, CAPO achieves significant improvements in sample efficiency for large language model reasoning tasks without substantial hyperparameter tuning.
Read the full article at arXiv cs.LG (ML)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
25
Comments
AN
Ali NematiWritten by Ali