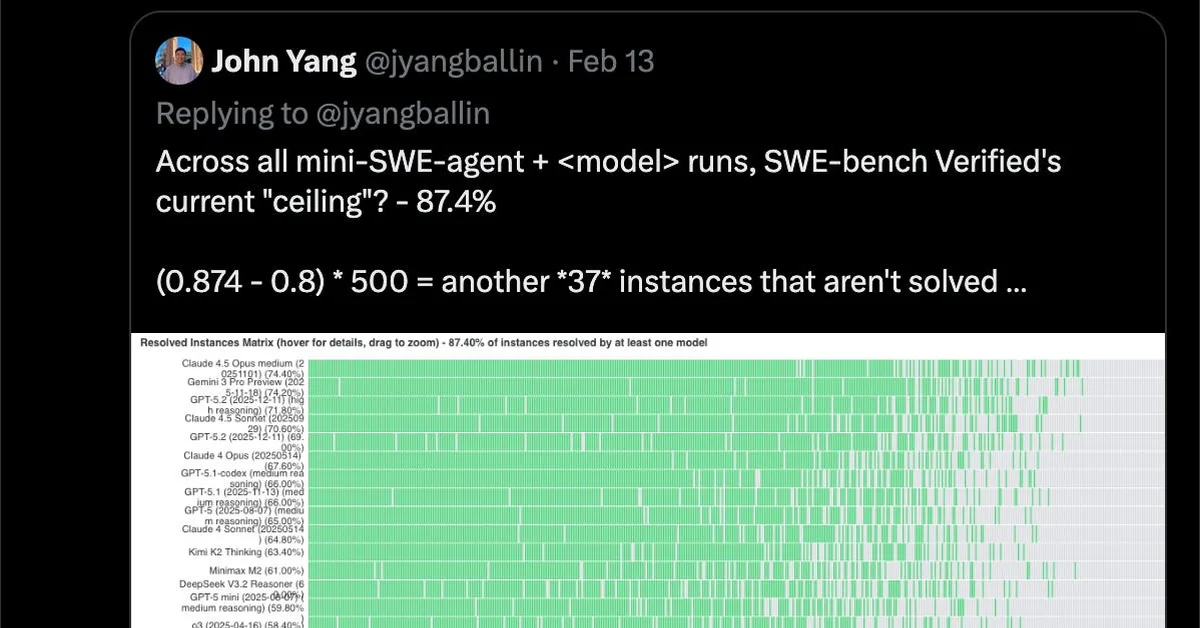
The discussion revolves around issues with the SQuAD-like dataset used for evaluating models on GitHub repositories, specifically focusing on contamination and unfair tests. Contamination occurred due to the open-source nature of the data, allowing models to potentially access and reuse specific repository details. Additionally, a deep dive into problems that models couldn't solve revealed overly narrow or unfair tests, where passing required implementation details not specified in the problem description. This analysis highlights the need for more robust evaluation methods to ensure fair assessment of model capabilities.
Read the full article at Latent Space
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.