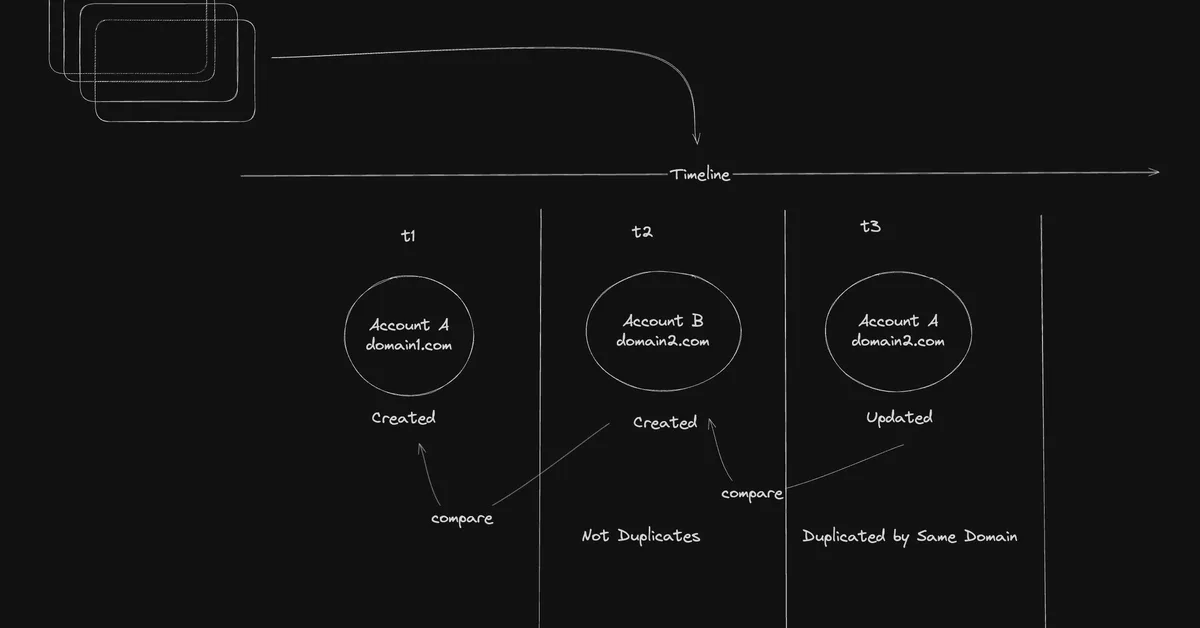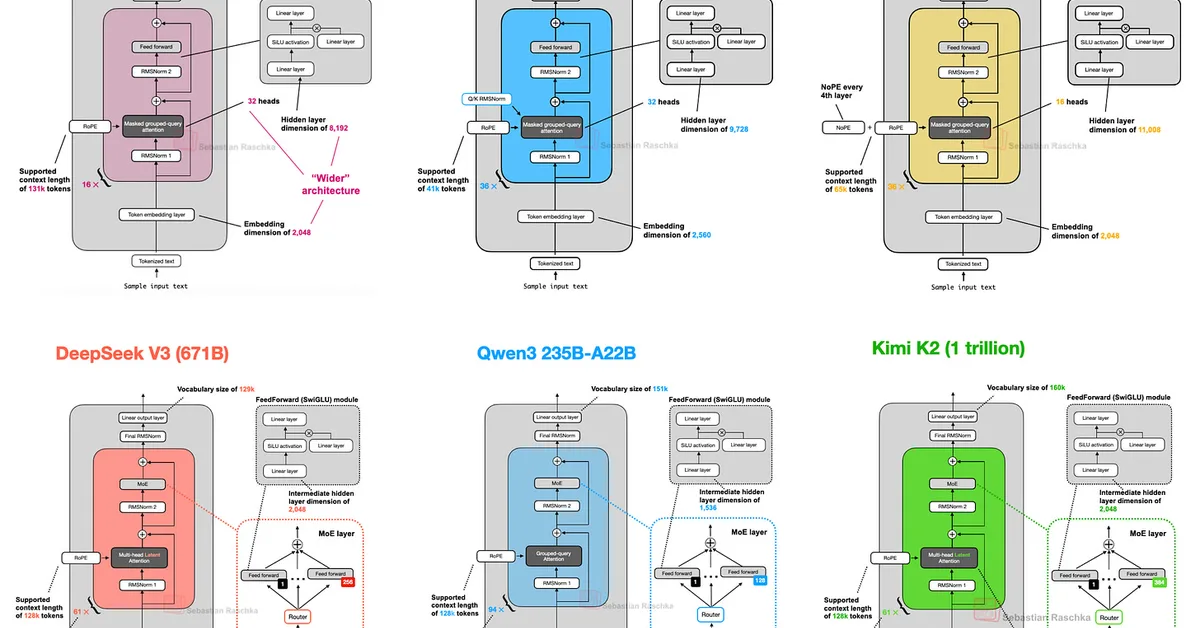
Deep LLM architectures like DeepSpeed's DeepMo and OLMo 2 from Meta have introduced unique architectural choices beyond traditional Multi-Head Attention (MHA). DeepMo utilizes a deep network architecture with multiple layers of attention to enhance performance, while OLMo 2 focuses on normalization techniques. It employs Post-Norm (placing RMSNorm after the attention and FeedForward modules within residual connections) instead of Pre-Norm used in most contemporary LLMs like GPT-3 or Llama. Additionally, OLMo 2 introduces QK-norm to further refine its architecture. These design choices aim to improve training stability and model performance.
Read the full article at Ahead of AI
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.