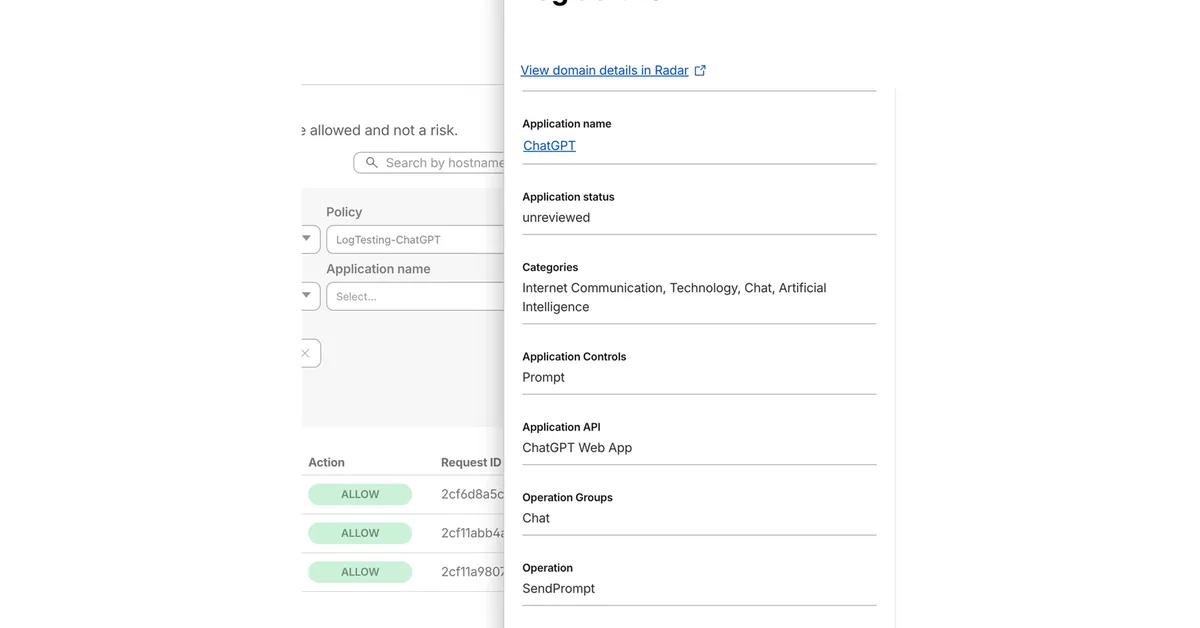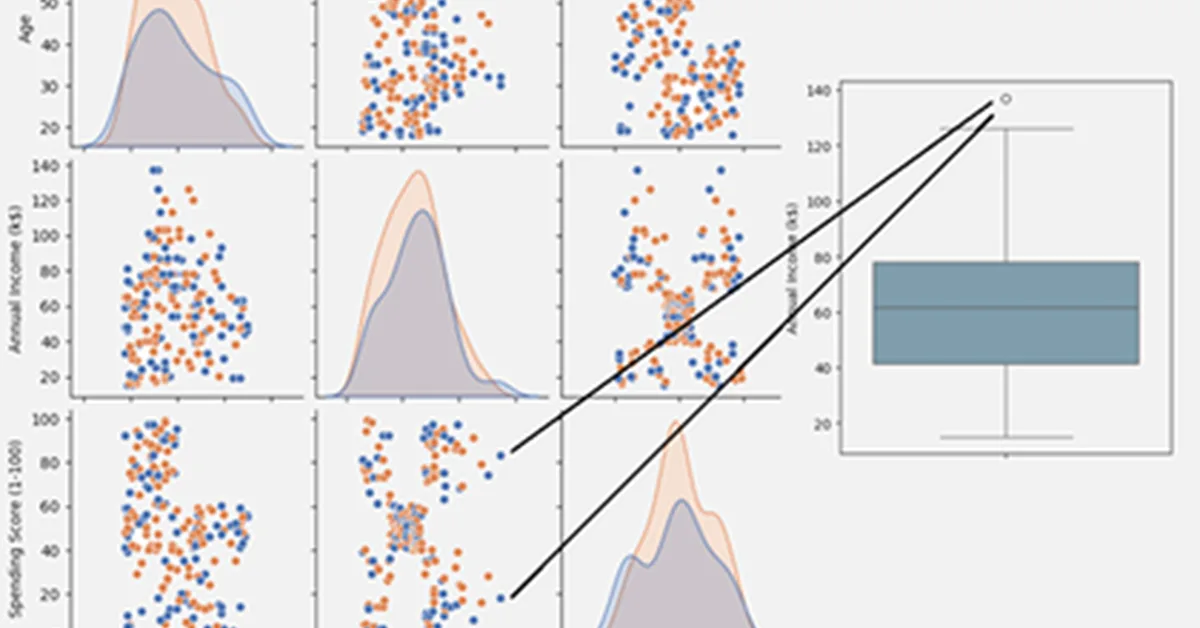
The article explores feature selection and outlier detection techniques to refine a dataset before applying clustering algorithms. Mutual Information (MI) is used to evaluate the importance of features in defining meaningful patterns within the data. The analysis reveals that 'Spending Score' and 'Annual Income' are dominant, while 'Age' shows moderate significance. Notably, 'Gender' has very low MI scores, suggesting it adds little value and could introduce noise. Outlier detection identifies two anomalies in the 'Annual Income' feature, which are removed to create a cleaner dataset for further analysis. The cleaned data maintains similar MI score rankings as the original, confirming the robustness of the identified patterns. Based on these insights, the article prepares three configurations of the dataset: one with all features including outliers, another without outliers but retaining all features, and a final version excluding 'Gender' to enhance clustering performance.
Read the full article at Towards AI - Medium
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.