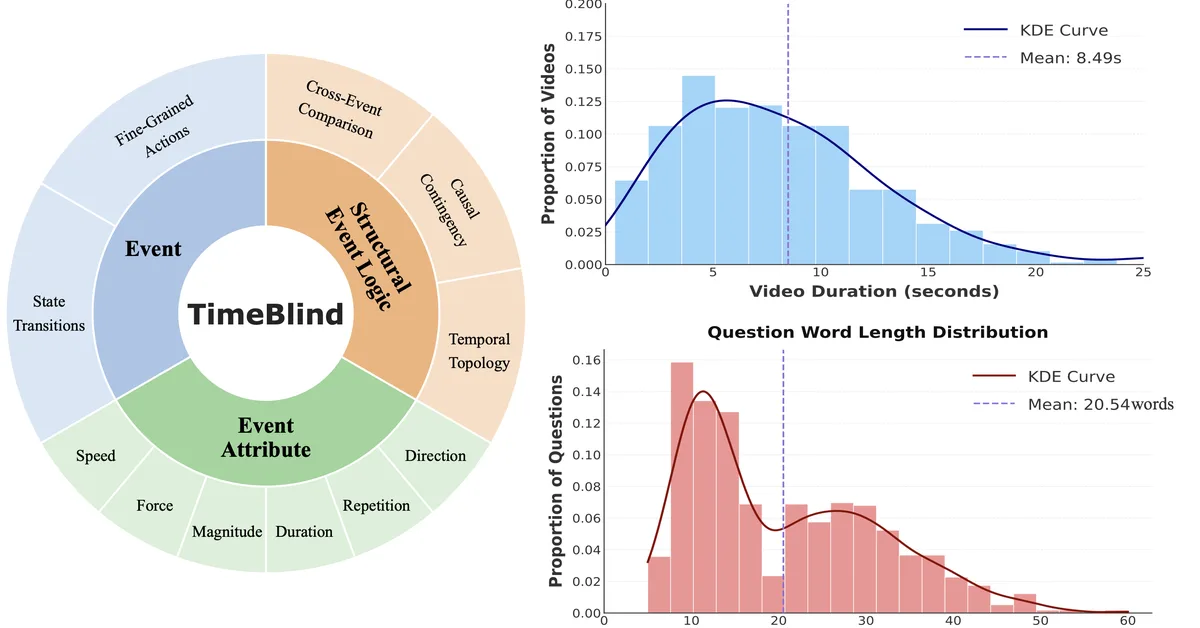
TimeBlind is a new benchmark designed to assess the spatio-temporal understanding capabilities of multimodal large language models in videos, revealing that even advanced models struggle with temporal reasoning and rely on static visual cues. This highlights the need for improved methods in developing video LLMs capable of true temporal comprehension.
Read the full article at arXiv cs.CV (Vision)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
14
Comments
AN
Ali NematiWritten by Ali