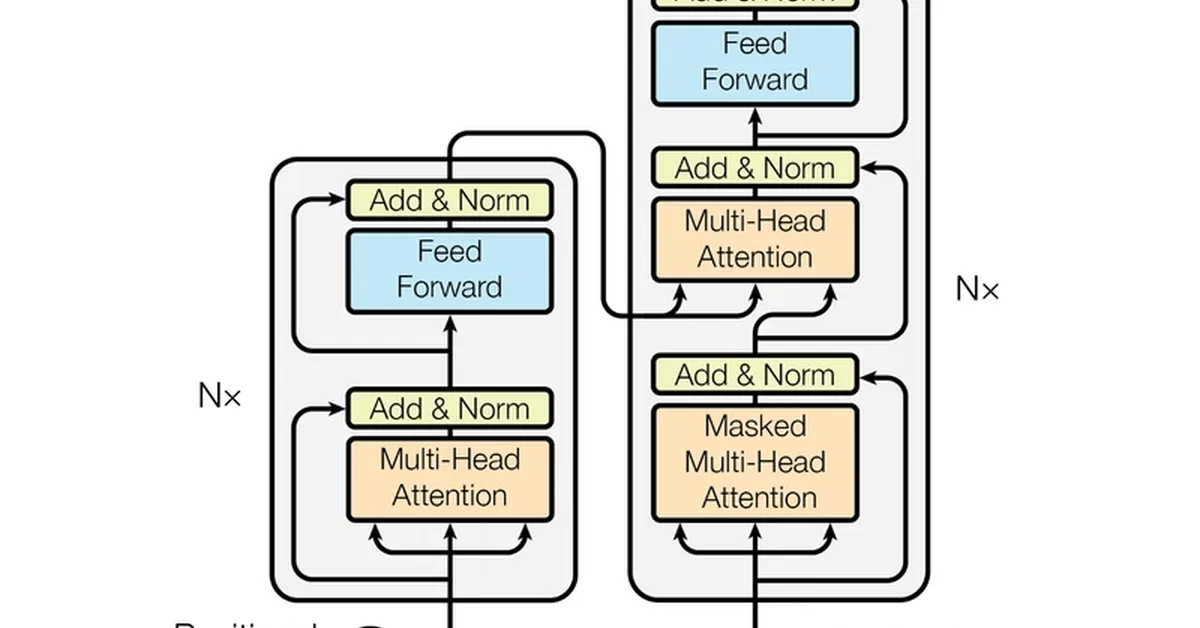
The article provides a detailed explanation of the attention mechanism in transformers, focusing on the steps involved in calculating attention scores and converting them into probabilities through scaling and softmax functions. It explains why scaling is necessary to prevent numerical instability during training and how softmax normalizes scores into probabilities that sum up to 100%, highlighting the highest score while suppressing lower ones. The piece also discusses the concept of "Attention Heads," where dimensions are divided into smaller chunks for specialized processing, enhancing the model's ability to capture different aspects of relationships within sentences.
Read the full article at DEV Community
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.