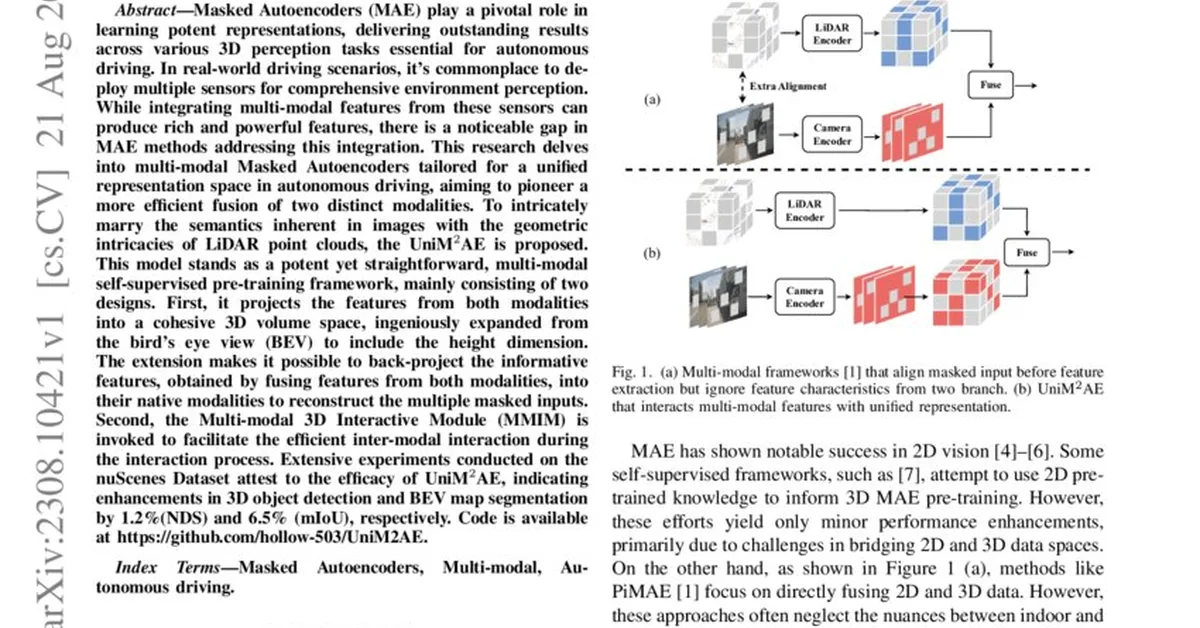
Researchers propose Unified-GRPO, a method that uses reinforcement learning to optimize image-to-text understanding and text-to-image generation tasks under an Auto-Encoder framework, where text serves as the intermediate representation. This approach enhances both I2T fine-grained visual perception and T2I fidelity by fostering mutual improvement through reconstruction objectives, offering content creators more accurate and comprehensive multimodal models.
Read the full article at arXiv cs.CV (Vision)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
6
Comments
AN
Ali NematiWritten by Ali