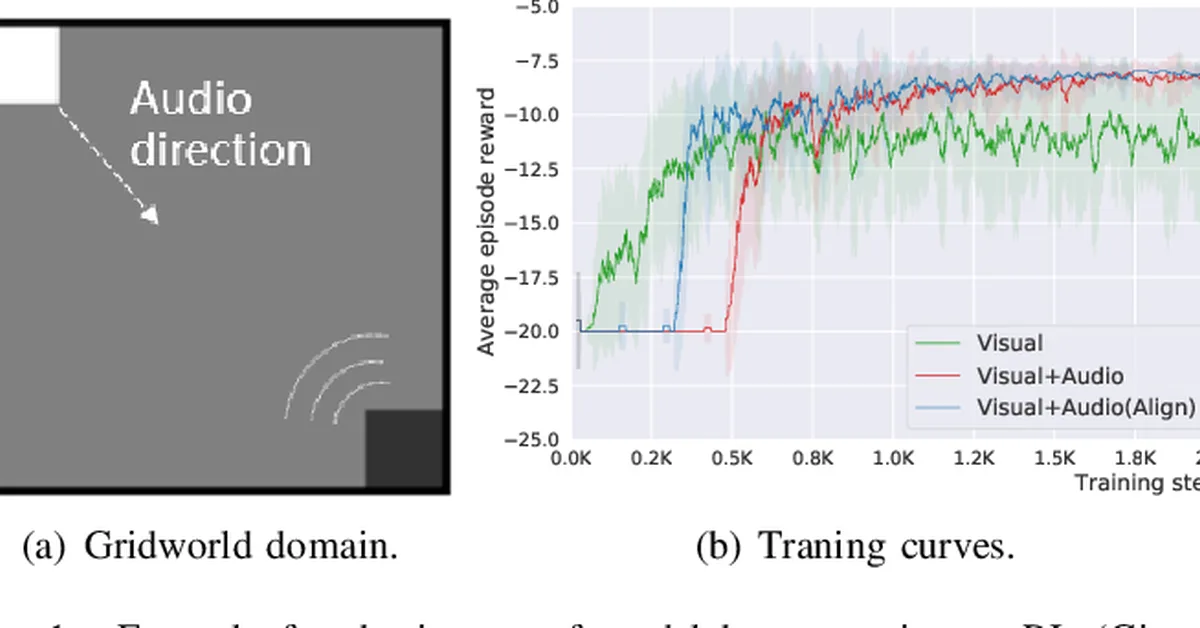
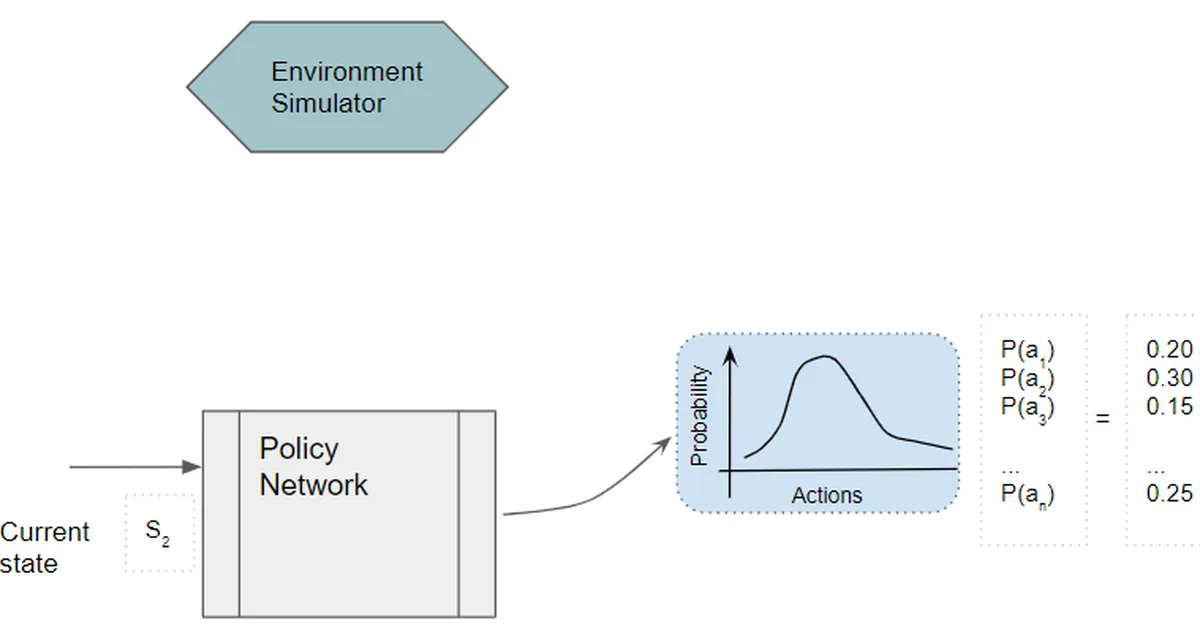
Researchers introduced VESPO, a new method for stable off-policy training of large language models in reinforcement learning, addressing policy staleness and asynchronous training issues through variance reduction techniques. This advancement is crucial for content creators as it promises more reliable and efficient training processes for complex AI models.
Read the full article at arXiv cs.LG (ML)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
19
Comments
AN
Ali NematiWritten by Ali