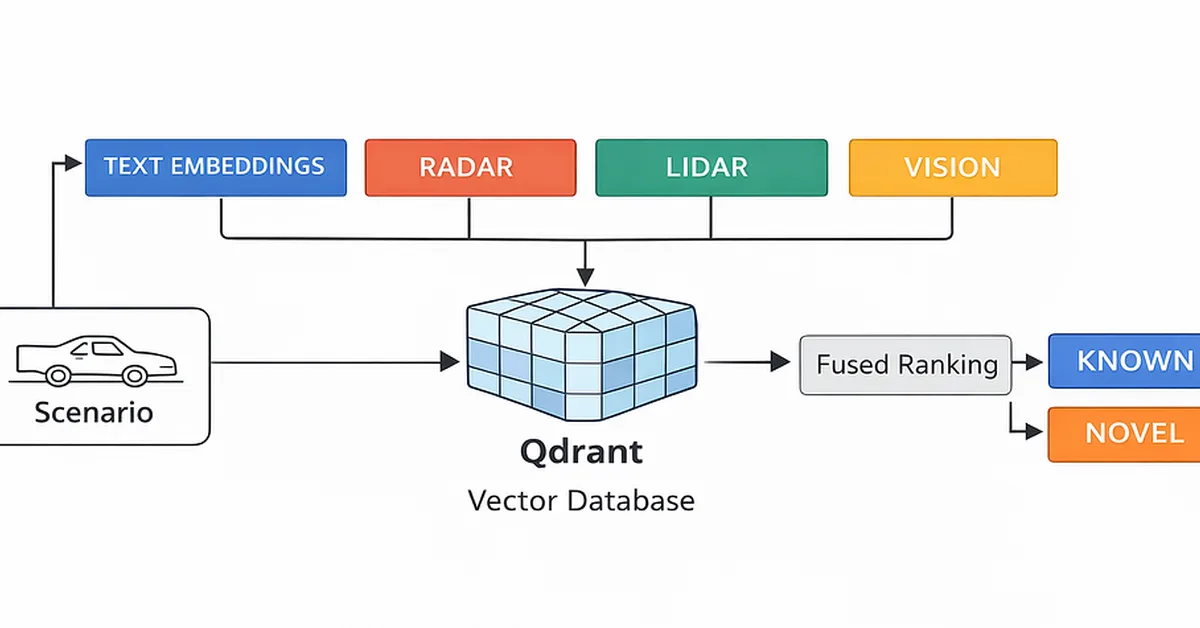
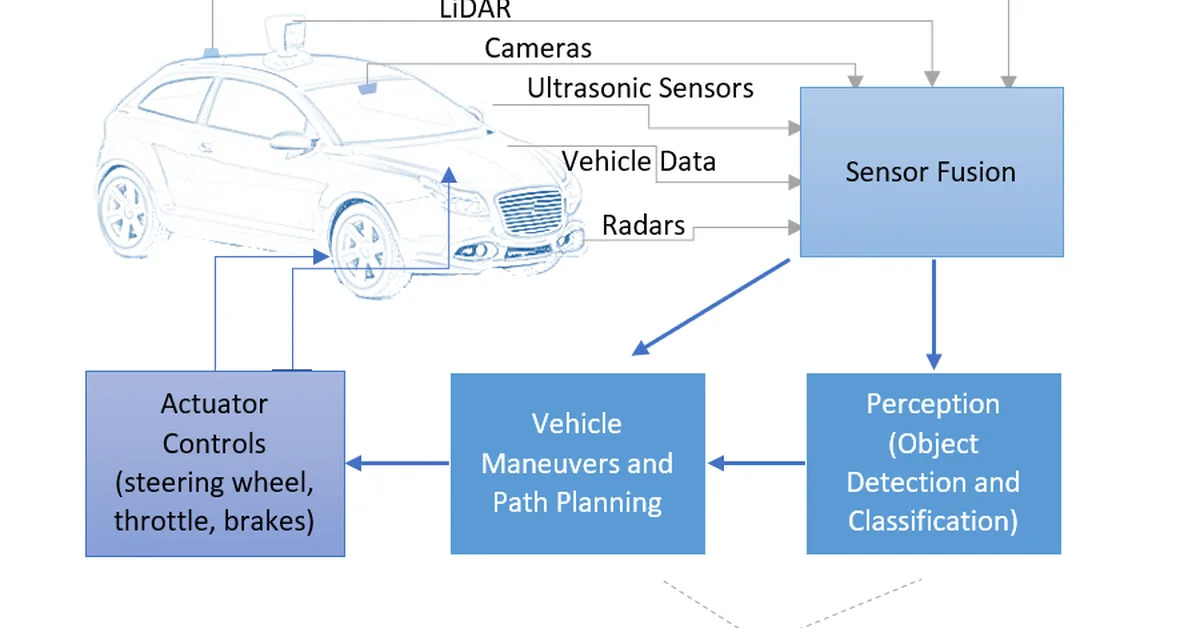
Researchers introduced VGGDrive, a new architecture that enhances vision-language models for autonomous driving by integrating cross-view 3D geometric grounding capabilities. This innovation improves performance across various autonomous driving tasks, highlighting the potential of combining mature 3D foundation models with VLMs to advance autonomous vehicle technology. Content creators should focus on how multidisciplinary approaches can unlock new functionalities in AI systems.
Read the full article at arXiv cs.CV (Vision)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
4
Comments
AN
Ali NematiWritten by Ali