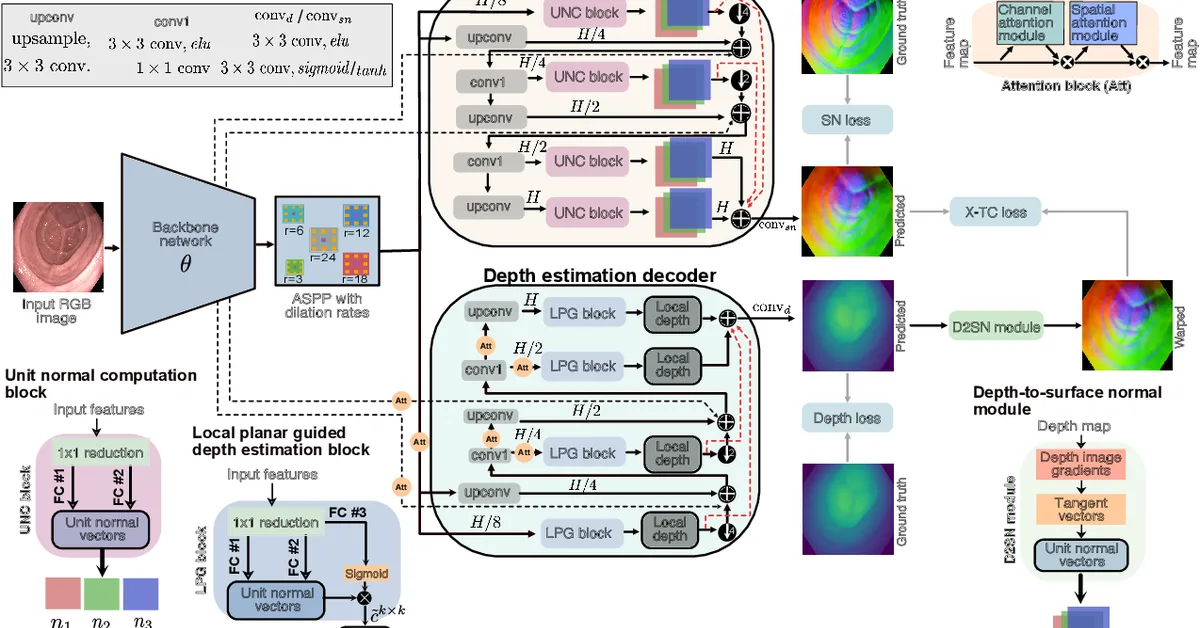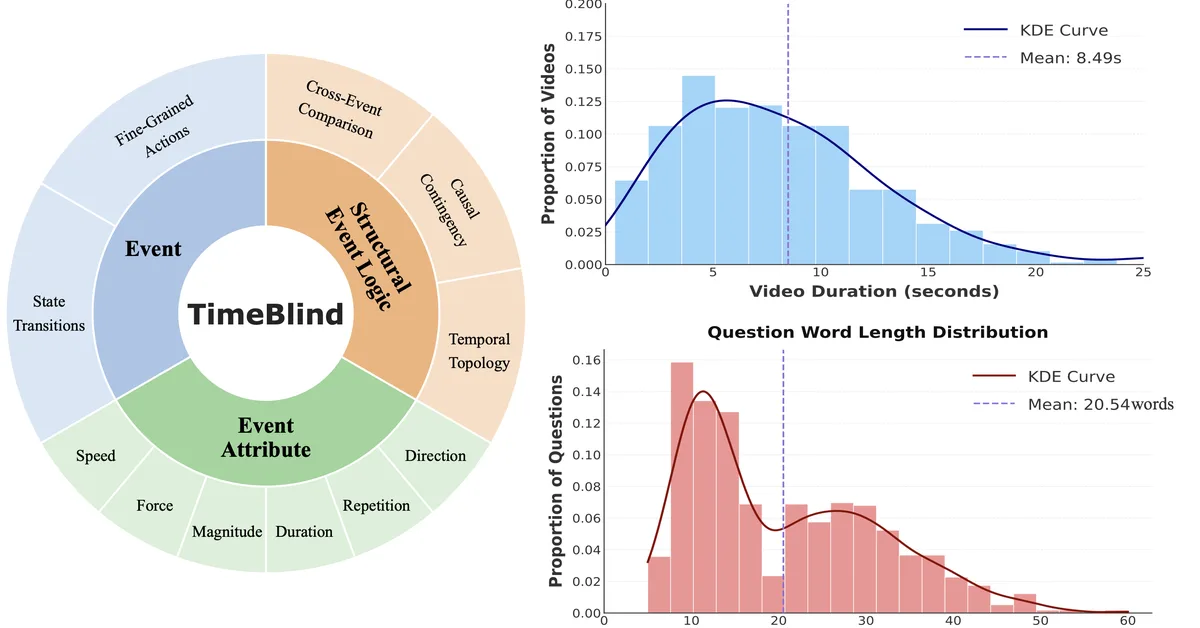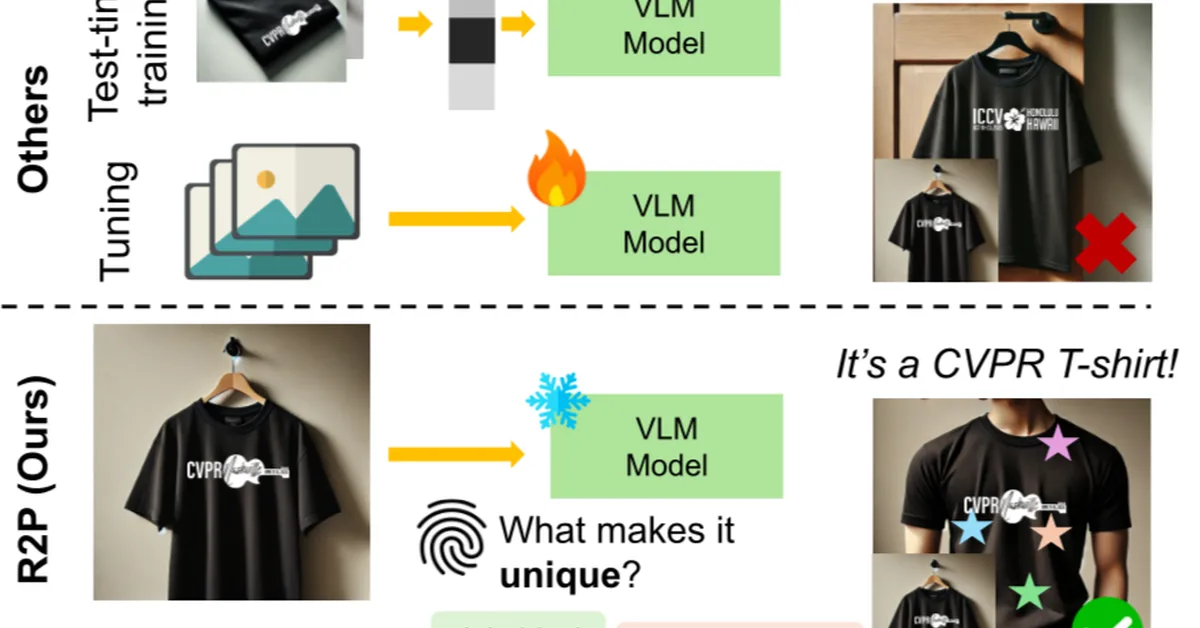
Researchers introduced VIGiA, a multimodal dialogue model that enhances understanding and reasoning of complex instructional video actions by integrating visual and textual data in real-time interactions. This advancement is crucial for content creators as it significantly improves user engagement and guidance accuracy in instructional videos, surpassing current models with over 90% accuracy in plan-aware tasks.
Read the full article at arXiv cs.CL (NLP)
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
14
Comments
AN
Ali NematiWritten by Ali