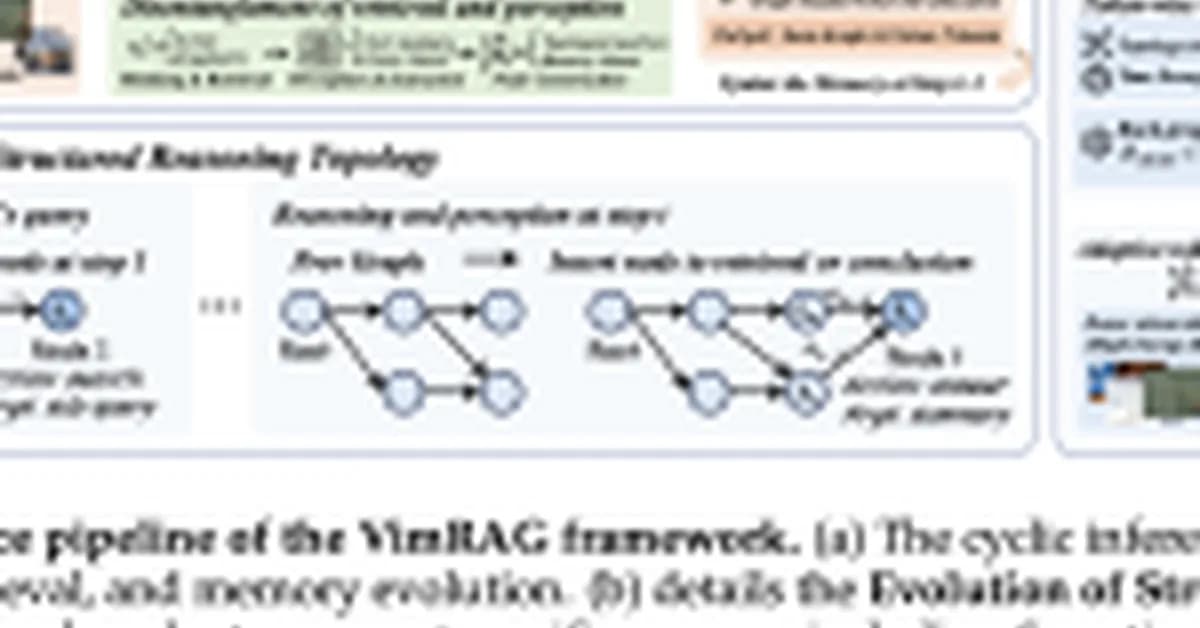
Researchers from Alibaba's Tongyi Lab have developed VimRAG, a multimodal Retrieval-Augmented Generation (RAG) framework designed to handle large volumes of visual data more efficiently. Key aspects include:
-
Multimodal Memory Graph: Replaces linear interaction history with a dynamic directed acyclic graph that tracks the agent’s reasoning state across steps, preventing repetitive queries and state blindness.
-
Graph-Modulated Visual Memory Encoding: Solves the problem of allocating high-resolution tokens to the most important retrieved evidence based on semantic relevance, topological position in the graph, and temporal decay.
-
Graph-Guided Policy Optimization (GGPO): Fixes issues with standard outcome-based rewards by using the graph structure to mask misleading gradients at the step level.
-
Pilot Study Results: Show that selectively retaining relevant vision tokens achieves the best accuracy-efficiency trade-off, outperforming both raw visual storage and text-only compression approaches.
-
Benchmark Performance: VimRAG outperforms all baselines across nine benchmarks on a unified corpus of approximately 200k interleaved multimodal items, scoring 50.1 overall on Qwen3-VL-8B-Instruct versus 43
Read the full article at MarkTechPost
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.

![[AINews] The Unreasonable Effectiveness of Closing the Loop](/_next/image?url=https%3A%2F%2Fmedia.nemati.ai%2Fmedia%2Fblog%2Fimages%2Farticles%2F600e22851bc7453b.webp&w=3840&q=75)



