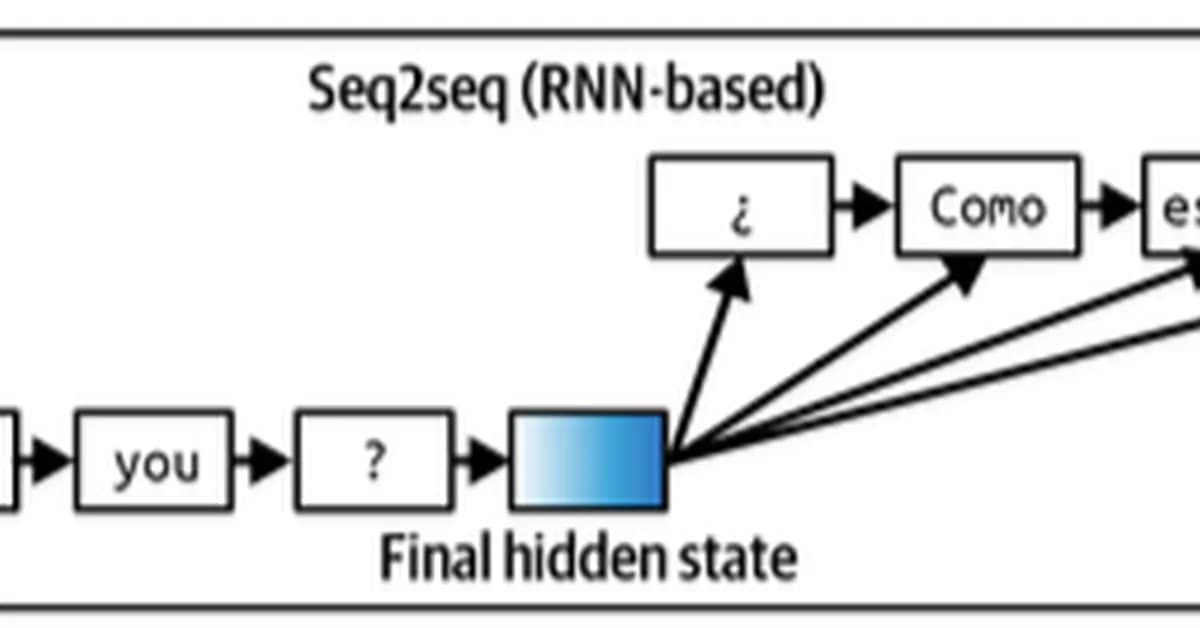
The provided code sets up a simple English-to-French translation model using an Encoder-Decoder architecture with attention. Here's a breakdown of the key components and how they work together:
Key Components
-
Encoder:
- Embeds input sequences into dense vectors.
- Processes these embeddings through a GRU (Gated Recurrent Unit) to generate context-aware representations for each time step.
-
Decoder with Attention:
- Takes the last hidden state from the encoder as its initial state.
- At each decoding step, it generates an output word and computes attention weights over all encoder outputs.
- Combines the decoder's current hidden state with weighted sums of encoder outputs (context vector) to generate predictions.
-
Training Loop:
- The model is trained using cross-entropy loss between predicted words and ground truth target sequences.
- Training involves iterating through each time step in the output sequence, generating predictions, computing losses, and updating weights via backpropagation.
Attention Mechanism
The attention mechanism allows the decoder to focus on different parts of the input sentence at each decoding step. This is crucial for handling long sentences where maintaining context over many steps would otherwise be challenging.
In your
Read the full article at Towards AI - Medium
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
4
Tags
Contents

Ali NematiWritten by Ali
![[AINews] The Unreasonable Effectiveness of Closing the Loop](/_next/image?url=https%3A%2F%2Fmedia.nemati.ai%2Fmedia%2Fblog%2Fimages%2Farticles%2F600e22851bc7453b.webp&w=3840&q=75)



