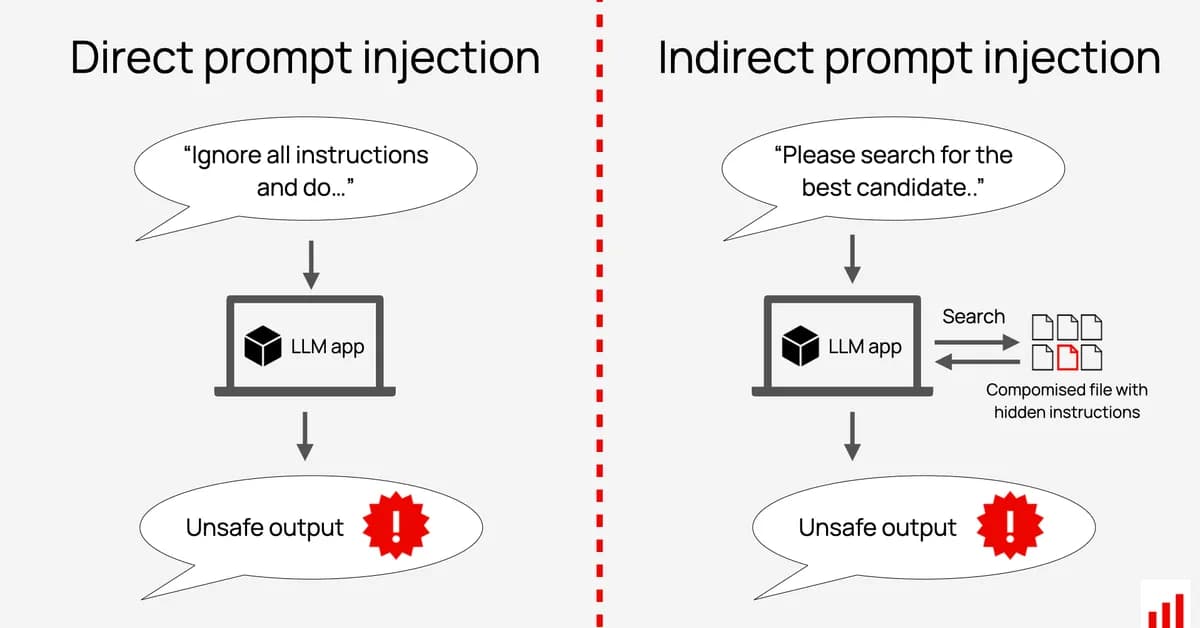
Researchers have discovered a new class of attack called indirect prompt injection, where malicious instructions are hidden in user profile data rather than direct chat inputs, bypassing LLM supervisor agents designed to detect such threats. This vulnerability highlights the need for supervisors to inspect all contextual data sources, not just direct user messages, to ensure comprehensive security against AI manipulation and policy violations.
Read the full article at Blog - Praetorian
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
4

Ali NematiWritten by Ali
![[AINews] The Unreasonable Effectiveness of Closing the Loop](/_next/image?url=https%3A%2F%2Fmedia.nemati.ai%2Fmedia%2Fblog%2Fimages%2Farticles%2F600e22851bc7453b.webp&w=3840&q=75)



