The explanation provided delves into the inner workings of large language models (LLMs) like Claude, focusing on several key aspects: tokenization, context window limitations, autoregressive generation, attention mechanism, and temperature control. Here's a summary and some additional insights:
Key Concepts
-
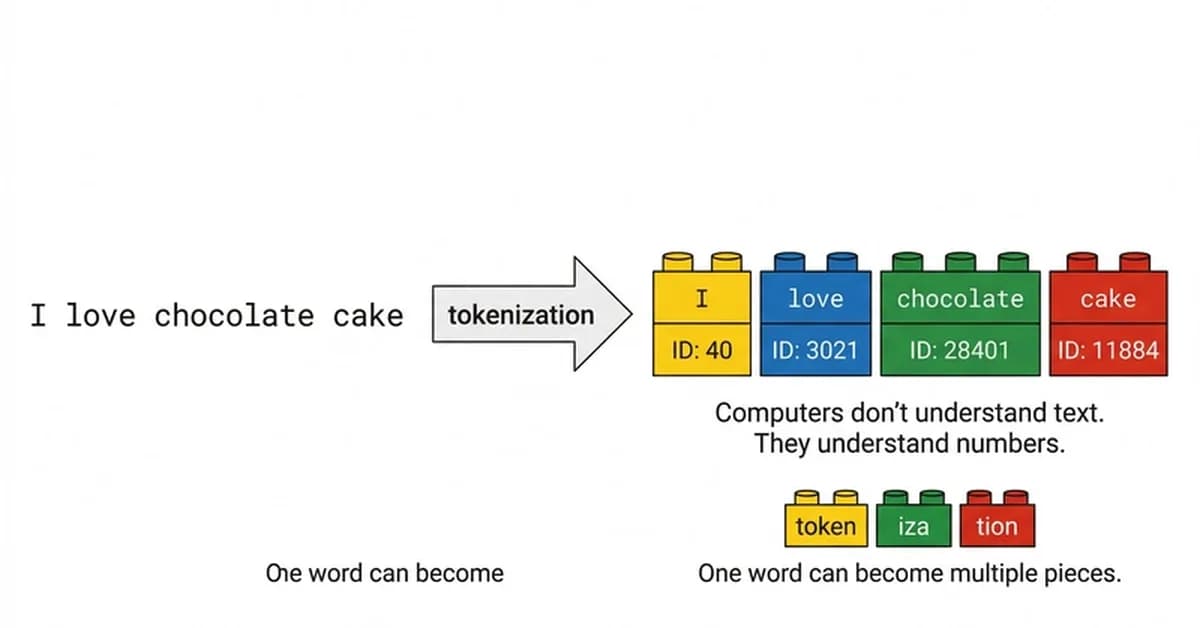
Tokenization:
- LLMs break down input text into tokens, which are the basic units of computation.
- The size of these tokens affects how much information they can carry (e.g., subword tokenizers like BPE vs word-level tokenizers).
-
Context Window:
- Models have a fixed context window that limits the amount of past input they can consider when generating text.
- For Claude Opus 4.6, this is around 200K tokens (approximately 32K words).
- The effective usable space for Portuguese content might be smaller due to linguistic differences in tokenization.
-
Autoregressive Generation:
- Models generate output one token at a time, with each subsequent token dependent on the entire sequence of previous tokens.
- This process is sequential and can lead to errors accumulating over time as the model generates longer sequences.
-
**
Read the full article at DEV Community
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
2
Tags
Contents

Ali NematiWritten by Ali
![[AINews] The Unreasonable Effectiveness of Closing the Loop](/_next/image?url=https%3A%2F%2Fmedia.nemati.ai%2Fmedia%2Fblog%2Fimages%2Farticles%2F600e22851bc7453b.webp&w=3840&q=75)



