The approach you've described is a sophisticated way of managing context and retrieval in multi-agent systems, particularly when dealing with complex queries that span multiple data sources or require analysis from different perspectives. Here's a breakdown of the key components and how they fit together:
1. Ontology Management
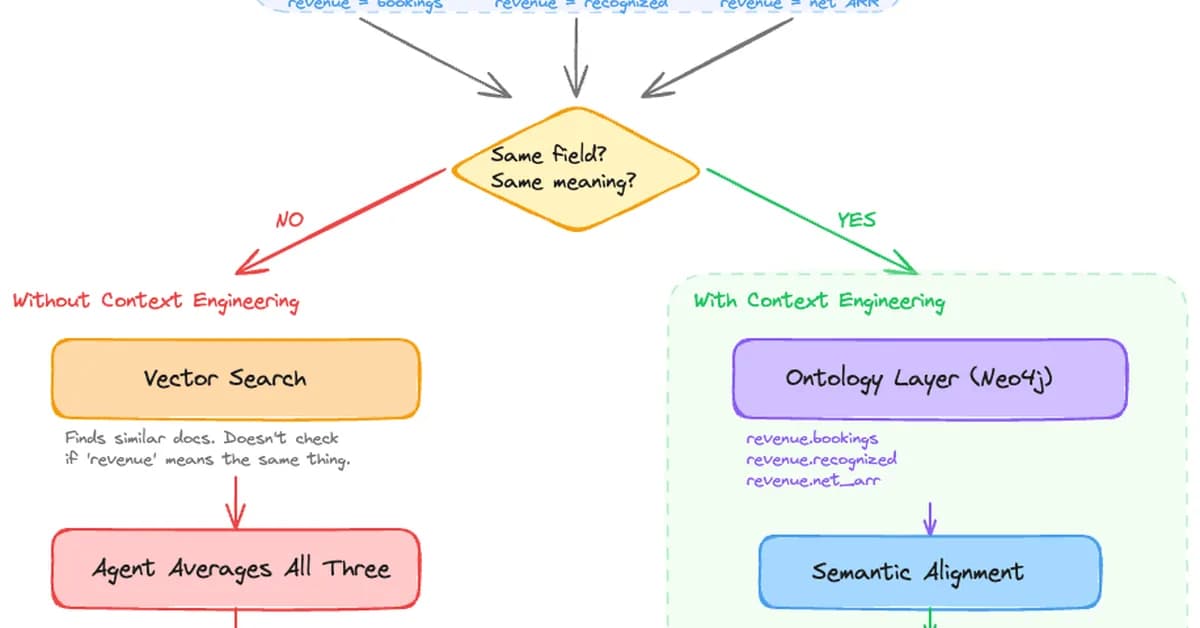
- Concept Disambiguation: The ontology helps to disambiguate concepts (e.g., "revenue") by defining variants ("recognized revenue", "ARR", etc.) and their authoritative sources.
- Context Metadata: Each concept is tagged with metadata such as confidence, extraction method, validation status, and source system. This ensures that the context provided to agents is accurate and trustworthy.
2. Query Resolution
- User Query Parsing: The
resolveQueryContextfunction parses user queries to extract temporal and organizational scopes. - Concept Disambiguation: For each ambiguous concept in the query, the system resolves it by finding the most relevant variant based on disambiguation hints (e.g., "ASC 606 recognized revenue").
3. Context-Aware Retrieval
- Pre-Vector Search Filtering: Before querying the vector store, the system filters
Read the full article at Towards AI - Medium
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
2
Tags
Contents

Ali NematiWritten by Ali
![[AINews] The Unreasonable Effectiveness of Closing the Loop](/_next/image?url=https%3A%2F%2Fmedia.nemati.ai%2Fmedia%2Fblog%2Fimages%2Farticles%2F600e22851bc7453b.webp&w=3840&q=75)



