The article discusses different methods for hyperparameter tuning in machine learning models and their efficiency when dealing with expensive evaluations. The main techniques covered are:
-
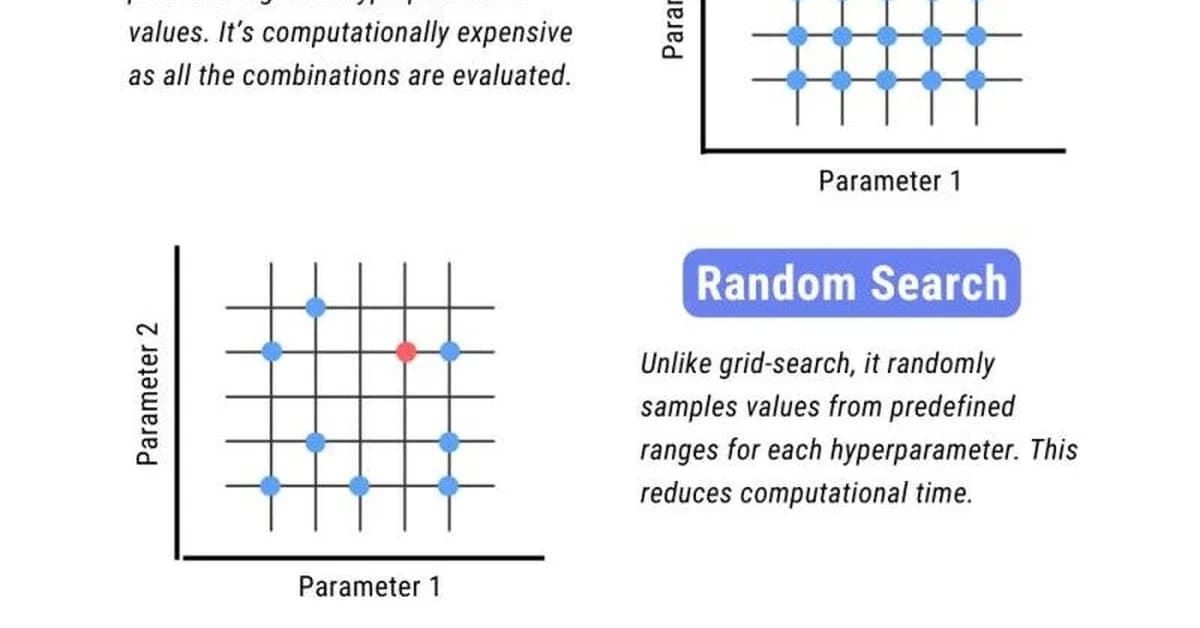
Grid Search: This method involves evaluating every point on a regular lattice defined by the Cartesian product of specified parameter lists. While thorough, it is inefficient because most points yield similar results due to the smooth nature of the accuracy surface for many models.
-
Random Search: Introduced by Bergstra and Bengio (2012), this approach replaces the grid with uniform random samples. Surprisingly, it often outperforms grid search even when using fewer evaluations. This is because random sampling can more densely cover important dimensions in the hyperparameter space, especially if only a subset of parameters significantly affects model performance.
-
Bayesian Optimization (GP): This method uses a probabilistic model to guide the search process based on previous evaluations. It starts with random samples and then uses the Gaussian Process (GP) model to predict promising regions for further exploration. The GP model helps in accelerating convergence by focusing evaluations where they are most likely to improve performance.
Key Points:
- Grid Search is exhaustive but inefficient, especially as dimensionality increases.
- Random Search can be more
Read the full article at DEV Community
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.

![[AINews] The Unreasonable Effectiveness of Closing the Loop](/_next/image?url=https%3A%2F%2Fmedia.nemati.ai%2Fmedia%2Fblog%2Fimages%2Farticles%2F600e22851bc7453b.webp&w=3840&q=75)



