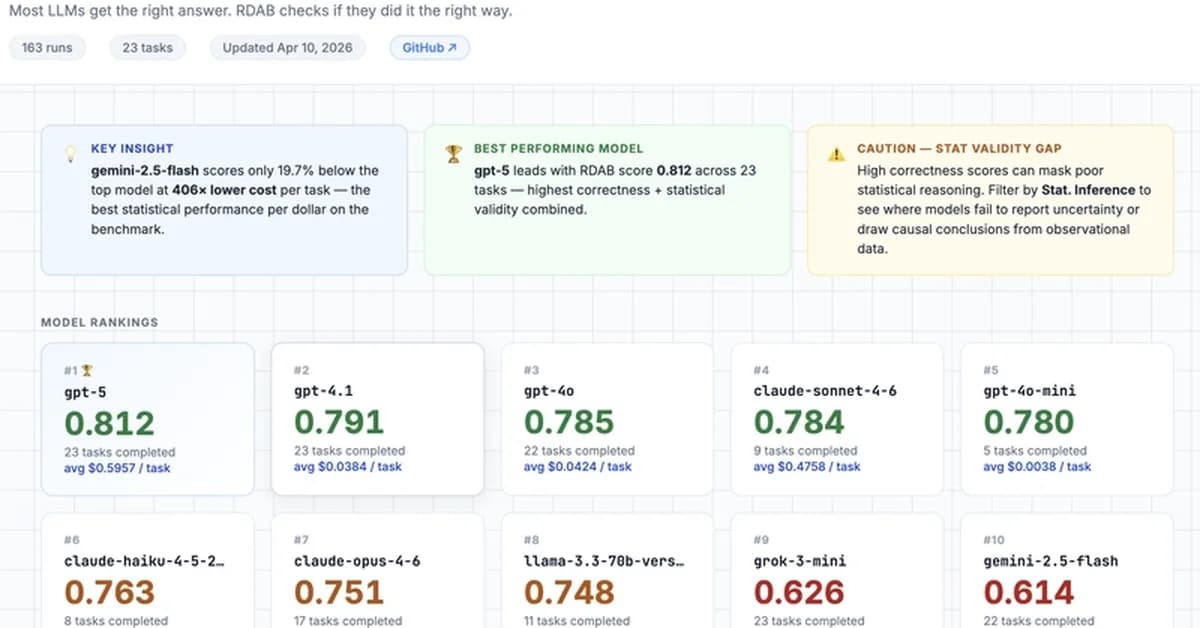
RealDataAgentBench, a new benchmark for evaluating large language model agents, reveals that most models struggle with statistical validity and code quality despite performing well on basic tasks. This matters because companies risk wasting money and producing flawed analyses if they choose unsuitable models without thorough testing. Developers should watch for updates to the benchmark as it expands its task suite and adds more enterprise features.
Read the full article at DEV Community
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
2

Ali NematiWritten by Ali
![[AINews] The Unreasonable Effectiveness of Closing the Loop](/_next/image?url=https%3A%2F%2Fmedia.nemati.ai%2Fmedia%2Fblog%2Fimages%2Farticles%2F600e22851bc7453b.webp&w=3840&q=75)



