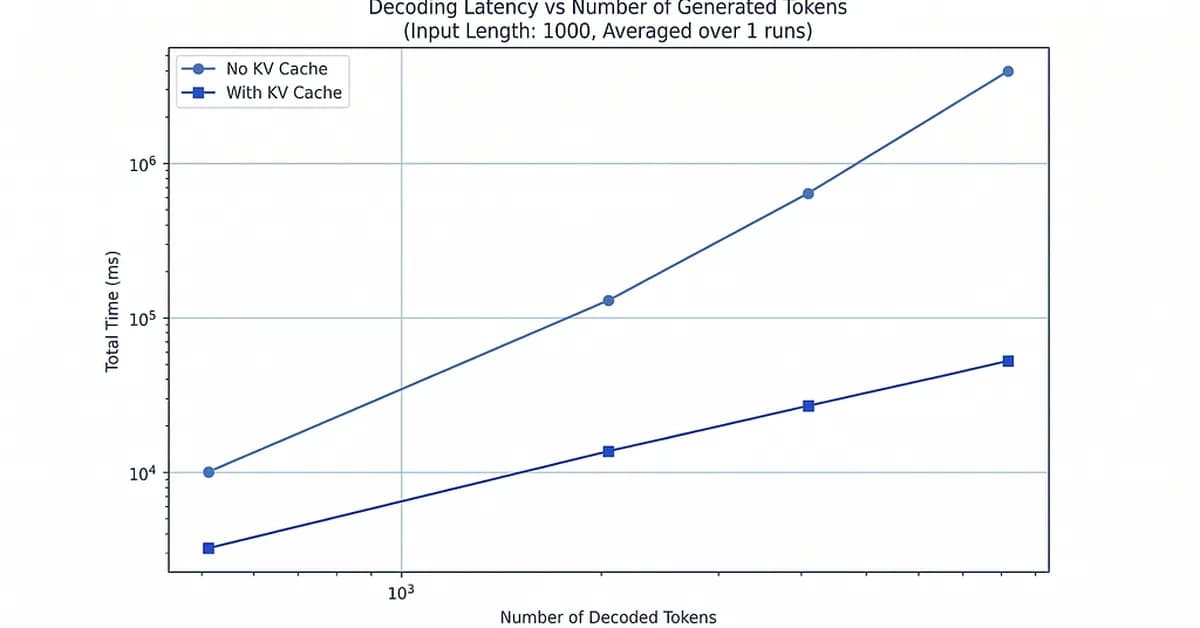
LLM inference systems transition from being computation-bound during prefill to memory-bound during decode due to repeated access to a growing KV (Key-Value) cache. During prefill, large dense computations keep the GPU fully utilized, but in decode, each step involves minimal computation and extensive data movement from the KV cache.
To address this bottleneck, techniques like Multi-Query Attention (MQA) and Grouped Query Attention (GQA) are employed to reduce the size of the KV cache. MQA shares a single set of Keys and Values across all attention heads, significantly decreasing memory usage but potentially limiting model specialization. GQA divides heads into smaller groups that share Keys and Values within each group while maintaining separate sets between groups, balancing memory efficiency with model performance.
These optimizations are crucial for managing the linear growth in KV cache size as sequence length increases, thereby improving overall system efficiency during decode.
Read the full article at Towards AI - Medium
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.

![[AINews] The Unreasonable Effectiveness of Closing the Loop](/_next/image?url=https%3A%2F%2Fmedia.nemati.ai%2Fmedia%2Fblog%2Fimages%2Farticles%2F600e22851bc7453b.webp&w=3840&q=75)



