Overview of the Research
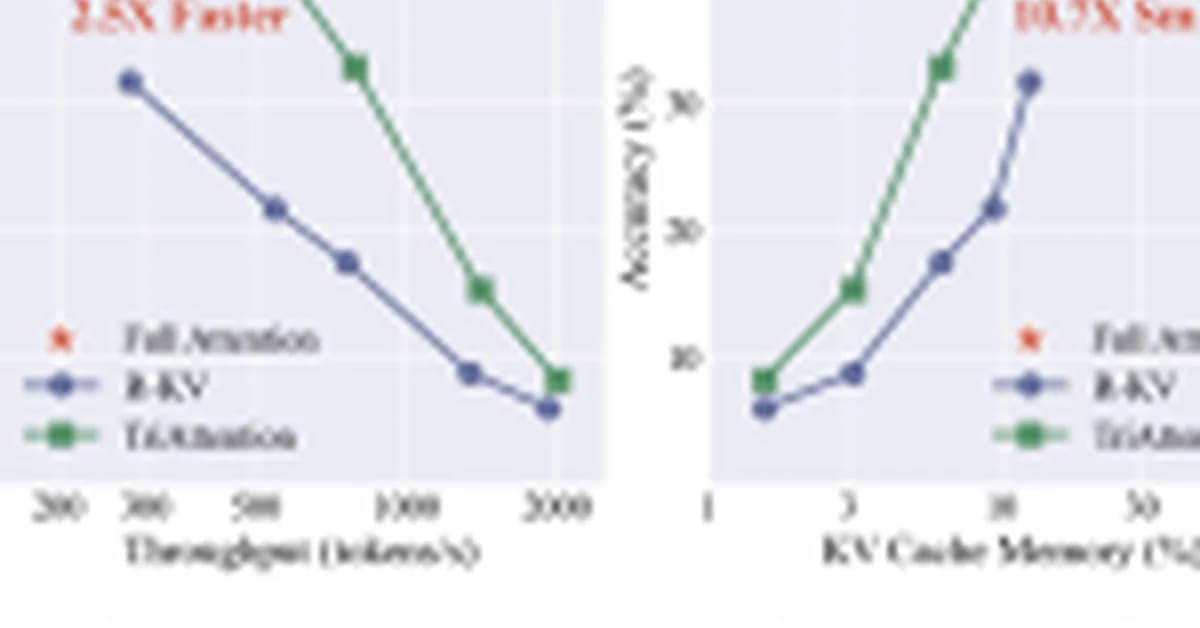
Researchers from MIT, NVIDIA, and Zhejiang University have introduced TriAttention, a novel KV (Key-Value) cache compression method designed to enhance the efficiency of large language models. TriAttention matches the accuracy of full attention while significantly reducing memory usage and improving throughput.
Key Insights and Innovations
1. Limitation of Existing Methods
Traditional KV cache compression methods like SnapKV and R-KV rely on recent post-RoPE (Rotary Positional Embedding) queries to estimate token importance. However, RoPEx rotates query vectors based on position, making it challenging to accurately predict the importance of tokens over time.
2. Query and Key Vector Concentration
The researchers discovered that pre-RoPEx Query and Key vectors cluster around stable, fixed centers across nearly all attention heads. This phenomenon, termed Q/K concentration, is consistent regardless of input content, token position, or domain. It holds true for various architectures like Qwen3, Qwen2.5, Llama3, and even Multi-head Latent Attention (MLA) models such as GLM-4.7-Flash.
3.
Read the full article at MarkTechPost
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.

![[AINews] The Unreasonable Effectiveness of Closing the Loop](/_next/image?url=https%3A%2F%2Fmedia.nemati.ai%2Fmedia%2Fblog%2Fimages%2Farticles%2F600e22851bc7453b.webp&w=3840&q=75)



