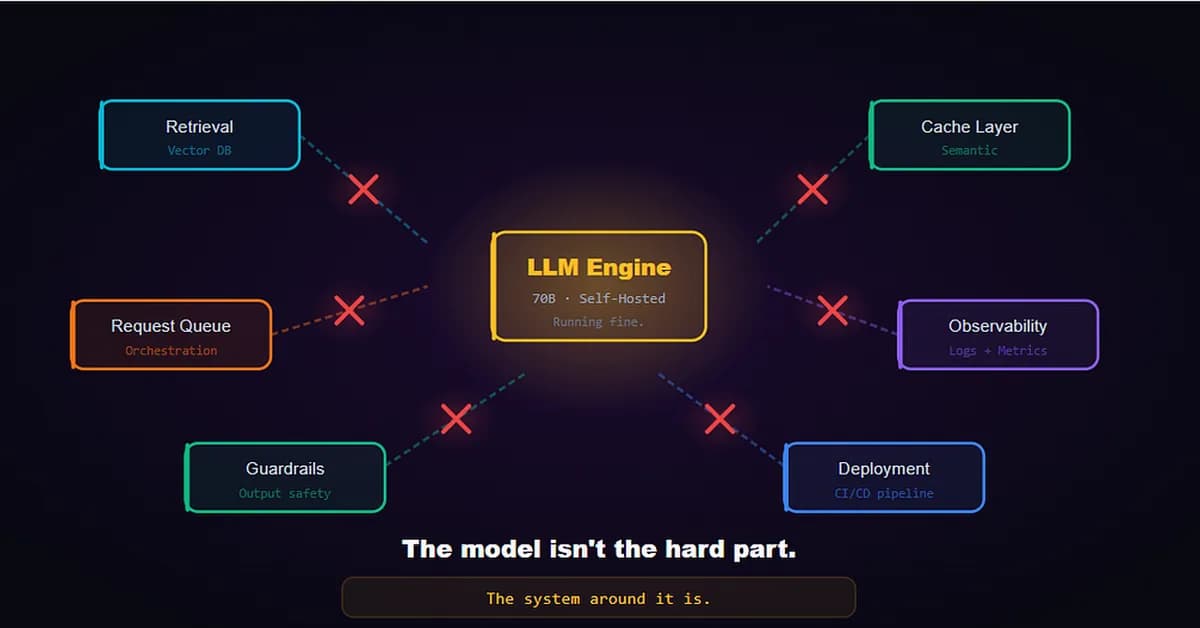
Running generative AI (GenAI) systems in production is more about managing complex distributed systems than simply deploying an API. Key challenges include designing for latency from day one, building robust observability into every layer of the pipeline, treating concurrency as a first-class architectural concern, and optimizing GPU usage through techniques like memory offloading, smart routing, and semantic caching.
Infrastructure plays a critical role in ensuring reliability:
- Deployment consistency is crucial; model-serving infrastructure should be templated and versioned.
- Staging environments do not accurately reflect production performance due to differences in hardware and traffic patterns. A "shadow production" environment that mirrors real-world conditions is recommended before going live.
- Continuous integration/continuous deployment (CI/CD) pipelines for AI services need evaluation gates to ensure new model versions pass regression tests against known good outputs.
Cost considerations are also significant:
- Self-hosting GenAI systems can be expensive, with costs measured in GPU-hours rather than per-token fees. For example, an A100 instance runs between $3 and $5 per hour.
- The global investment required to meet AI compute demand is projected to reach $6.7 trillion by 2030.
The takeaway is that GenAI is fundamentally a systems problem
Read the full article at Towards AI - Medium
Want to create content about this topic? Use Nemati AI tools to generate articles, social posts, and more.
233

Ali NematiWritten by Ali




